大模型推理并行策略总结
大模型推理过程中有很多种并行策略,如TP(Tensor Parallel),PP(Pipeline Parallel),DP(Data Parallel),EP(Expert Parallel),SP(Sequence Parallel)等。本文对这些并行场景进行总结,并结合vLLM分析如何在工程中实现。
1.Tensor Parallel
Tensor Parallel的核心原理就是将矩阵进行分块计算,常见的有RowLinear和ColumnLinear。以输入X,shape [B,s,h],权重W,shape为[h,h’]为例进行说明。
1.1 RowLinear
RowLinear表示对权重矩阵按行切分,同时也需要对输入X进行拆分,每一部分分布在不同的GPU上。推理过程需要先进行拆分,计算后再进行通信all-reduce。
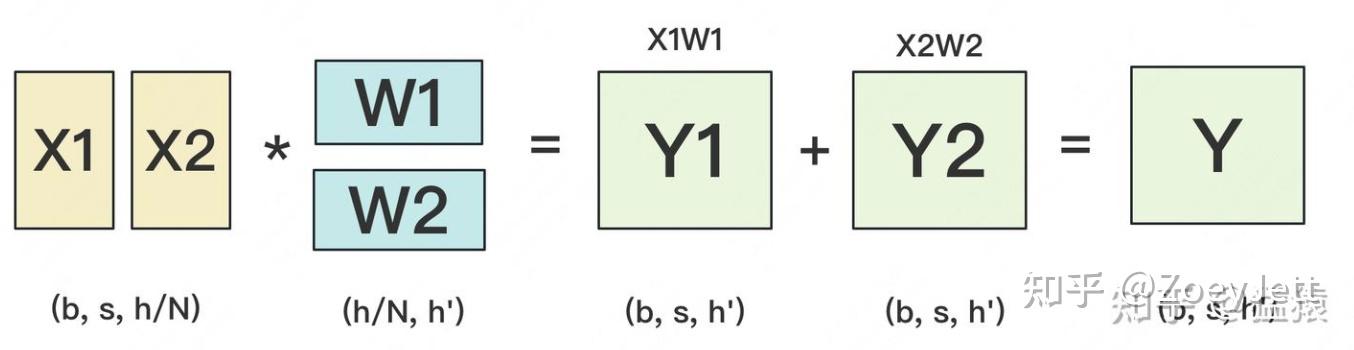
1.2 ColumnLinear
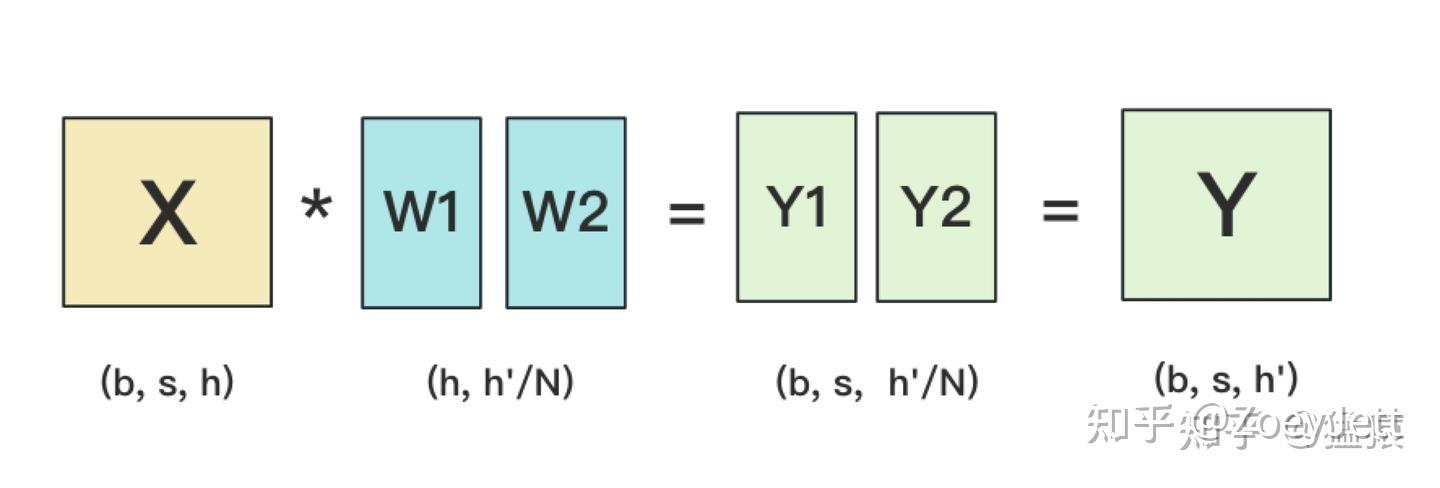
ColumnLinear表示对权重按列切分,输入X不需要切分,每块GPU上都是完整的输入,推理后需要对结果进行all-gather通信。
1.3 通信分析
TP在单次前向传播中会产生多次AllReduce通信。以上述MLP的组合为例,其前向传播会触发2次AllReduce-1。由于通信频率高,TP对GPU间的通信带宽要求极高,通常仅限于单个节点内的高速NVLink域内使用,跨节点的TP性能会急剧下降。
1.4 优缺点
- 优点:
- 显存效率高:模型参数和中间激活被切分,能显著降低单卡显存压力,支持超大规模模型-。
- 降低延迟:多个GPU并行处理同一请求,能有效加速计算,降低单个请求的响应时间(TTFT)。
- 缺点:
- 通信开销巨大:频繁的AllReduce通信会成为性能瓶颈,尤其是在跨节点时-。
- 扩展性受限:并行度受限于模型头数(head number)等维度,且跨节点扩展效率极低。
- 负载不均:在MoE模型中,单纯的TP可能导致部分专家闲置,计算资源利用不均。
2.Data Parallel
Data Parallel在前向过程中是最简单的并行方式,每张卡有完全相同的模型,模型和计算都是完全独立的。仅对多个请求进行分发给不同的GPU。也不需要进行通信和同步。
2.1 通信分析:
在推理场景下,不同DP实例处理的是独立的请求,它们之间不需要任何通信。唯一的通信发生在训练阶段,需要通过AllReduce来聚合所有副本的梯度。
2.2 优缺点
- 优点:
- 吞吐量高:近乎线性的吞吐量扩展能力,非常适合高并发场景。
- 实现简单:逻辑清晰,不涉及复杂的模型切分和集合通信。
- 缺点:
- 显存冗余:每个GPU都保存完整的模型参数和KV Cache,总显存消耗是单卡的
N倍。 - 模型规模受限:单个GPU必须能完整装下模型,无法解决超大模型的部署问题。
- 显存冗余:每个GPU都保存完整的模型参数和KV Cache,总显存消耗是单卡的
3.Pipeline Parallel
PP是按层切分的模型并行,它将模型的层划分为多个阶段(Stage),每个阶段分配给一个GPU,形成一个处理流水线
3.1 Shape切分与推导
- 切分方式:模型被纵向切分,每个GPU持有连续几层的完整权重。输入数据
X不切分,但在不同GPU间顺序流动。 - 前向推导:
Stage1(X) -> Stage2(Out₁) -> ... -> StageN(Outₙ₋₁) -> Y。每个GPU的输入是上一个GPU的完整输出。
3.2 通信分析
PP的通信仅发生在流水线阶段的边界,通信模式是点对点(P2P) 的,仅传递相邻阶段间的激活值和梯度。相比于TP,它的通信量小得多,因此更适合跨节点扩展。
3.3 优缺点
- 优点:
- 跨节点扩展性好:较低的通信开销使其成为跨节点扩展的首选。
- 减少长序列延迟:对于长上下文场景,通过Chunked Prefill将输入分块并行处理,可显著降低TTFT(有报告指出最高可降低67.9%)。
- 提升吞吐:在跨节点部署下,PP的Prefill吞吐量可达到纯TP的3.31倍。
- 缺点:
- 流水线气泡(Bubble):流水线启动和切换时存在设备空闲,导致GPU利用率不高。
- 单请求延迟瓶颈:若没有分块优化,单个请求的延迟由所有阶段的延迟和决定。
4. Expert Parallelism,EP
EP是MoE(混合专家)模型的专用并行策略。它将MoE层中不同的专家(Expert) 分布到不同的GPU上,每个GPU只负责计算分配给它的专家。
4.1 Shape切分与推导
- Shape切分与推导:
- 切分方式:对MoE层的专家权重进行切分。非MoE层(如Attention)保持完整或被TP切分。
- 前向推导:每个Token通过门控网络(Router) 被路由到Top-K个专家。这些专家可能位于不同的GPU上。
4.2 通信分析
EP的核心通信是All-to-All,用于Token分发和结果收集。例如,每个GPU将本地需要远程专家处理的Token发送出去,同时接收其他GPU发来需要本地专家处理的Token。其通信开销与专家的激活密度强相关。
4.3 优缺点
- 优点:
- 显著降低MoE显存:只切分专家权重,非MoE层保持完整,避免了对Attention层不必要的切分。
- 提升效率:通过与TP/DP组合,可提供更高的吞吐或更低的延迟。
- 缺点:
- 仅适用于MoE模型:对稠密模型无效。
- All-to-All通信瓶颈:在某些硬件或配置下,All-to-All通信可能成为瓶颈。
- 负载均衡挑战:需要配合负载均衡算法,防止部分专家过载。
5.Sequence Parallelism, SP
SP是DP的细粒度版本,它将单个序列沿长度维度切分到多个GPU上,旨在突破单卡对长序列处理的限制。
5.1 Shape切分与推导
- Shape切分与推导:
- 切分方式:将输入张量
X沿seq_len维度切分为多个连续或不连续的块,每个GPU处理一部分Token。 - 前向推导:每个GPU使用本地序列块计算局部的
Q/K/V。为了完成全局Attention,需要通信来获取其他GPU上的K/V。
- 切分方式:将输入张量
5.2 通信分析
根据实现方式不同,SP的通信模式主要有两种:
- Ring-Attention:采用环状的P2P通信,每个GPU将本地
K/V传递给下一个GPU。 - DeepSpeed Ulysses:采用All-to-All通信。在计算前,通过All-to-All将序列切分转换为注意力头的切分,使每个GPU能对完整的序列计算一个注意力头的子集,最后再用All-to-All换回序列切分。
5.3 优缺点
- 优点:
- 支持超长序列:能将支持的序列长度提升数倍(如3倍),突破单卡显存瓶颈。
- 提升长序列处理速度:通过并行处理可加速长序列推理,实现1.5-3.6倍的速度提升。
- 缺点:
- 仅对长序列有效:序列太短时,并行带来的收益会被通信开销抵消。
- 通信开销大:特别是All-to-All通信,可能成为长上下文推理的瓶颈。
- 实现复杂:需要对Attention等模块进行特殊修改,以处理跨卡依赖。
6.横向对比总结
| 维度 | TP (张量并行) | PP (流水线并行) | DP (数据并行) | EP (专家并行) | SP (序列并行) |
|---|---|---|---|---|---|
| 切分维度 | 单层内参数矩阵(行/列) | 模型的层(深度) | 数据批次(Batch) | MoE层的专家 | 序列长度(Sequence) |
| 切分粒度 | 最细 | 中等 | 粗 | 中等 | 中等 |
| 主要通信 | AllReduce(频繁) | P2P(阶段边界) | 无(推理)/ AllReduce(训练) | All-to-All | All-to-All / P2P (Ring) |
| 通信开销 | 高 | 低 | 极低(推理时无) | 中到高 | 高 |
| 适用场景 | 超大规模模型,降低延迟 | 跨节点扩展,处理超长序列 | 高并发,提升吞吐量 | 大规模MoE模型,降低显存 | 超长序列,突破长度限制 |
| 优点 | 高效降低延迟,显存效率高 | 跨节点扩展性强,减少长序列TTFT | 吞吐量高,实现简单 | MoE显存效率高,性能好 | 支持超长序列,加速长序列处理 |
| 缺点 | 通信开销大,跨节点扩展差 | 存在流水线气泡 | 显存冗余大,模型规模受限 | 仅适用MoE,有通信挑战 | 通信开销大,仅对长序列有效 |
在实践中,这些并行策略并非互斥,而是常被组合使用以实现最优部署,例如TP+PP实现跨节点大规模部署,DP+EP+SP实现长序列高并发推理。
选择并行策略的关键考量点:
- 模型规模与显存:首先判断单卡能否装下完整模型。
- 装不下 -> TP (模型参数巨大) 或 PP (模型层数极深)。
- 能装下 -> DP (追求高吞吐)。
- 序列长度与延迟:判断是否需要处理超长序列。
- 需要 -> SP (突破长度限制) 或 PP (分块Prefill降低延迟)。
- 不需要 -> 基本策略 (TP/DP)。
- 模型架构与硬件:
- MoE模型 -> 优先考虑EP。
- 多机多卡 -> PP是跨节点首选。
- 单机多卡 (NVLink) -> TP效率最高。
7.参考
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2026/04/21/LLM-parallel-mode/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)