Continuous Batching总结
大模型推理过程通常被分成prefill和decode两个阶段,prefill需要对整个输入序列进行计算,decode每一次只推理产生一个新的token。所以prefill通常被认为是计算限制(compute-bound),算力比较容易打满,decode阶段属于内存带宽限制(memory-bandwidth-bound),算力很难打满,需要在推理时进行组batch,提高算力利用率。
1.静态batch处理
传统的batch处理,也叫静态批处理,以下图为例,kvcache提前预分配的size为8。
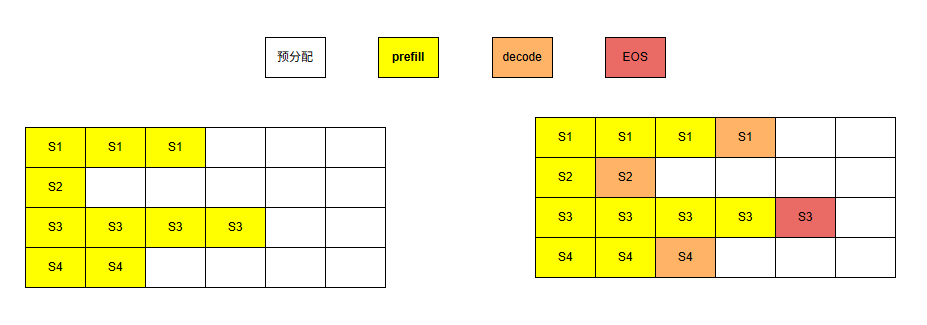
图中batch为4,白色为空闲区域。经过一轮计算后,序列S3完成了推理计算,但由于静态batch处理,需要等到所有序列完成计算才算结束,所以S3的资源并不会在结束之后立即释放,造成内存空间的浪费。再加上每个batch输入和输出的长度都不相等,导致需要对输入进行对齐padding,并给输出按照最大长度分配空间,极大程度造成内存空间的利用率低。
2.Continuous Batching
Continuous它不等待整个请求完成,而是在每一步生成时,把所有请求当前要处理的 token 合并成一个 batch,统一处理。
这就意味着:请求可以随时加入、随时结束,不用互相等待,GPU 资源能被一直打满。 Batching 的核心思想是按token批为单位处理,不按请求批处理。
我们以vLLM官方图里的示例进行一步一步解析:
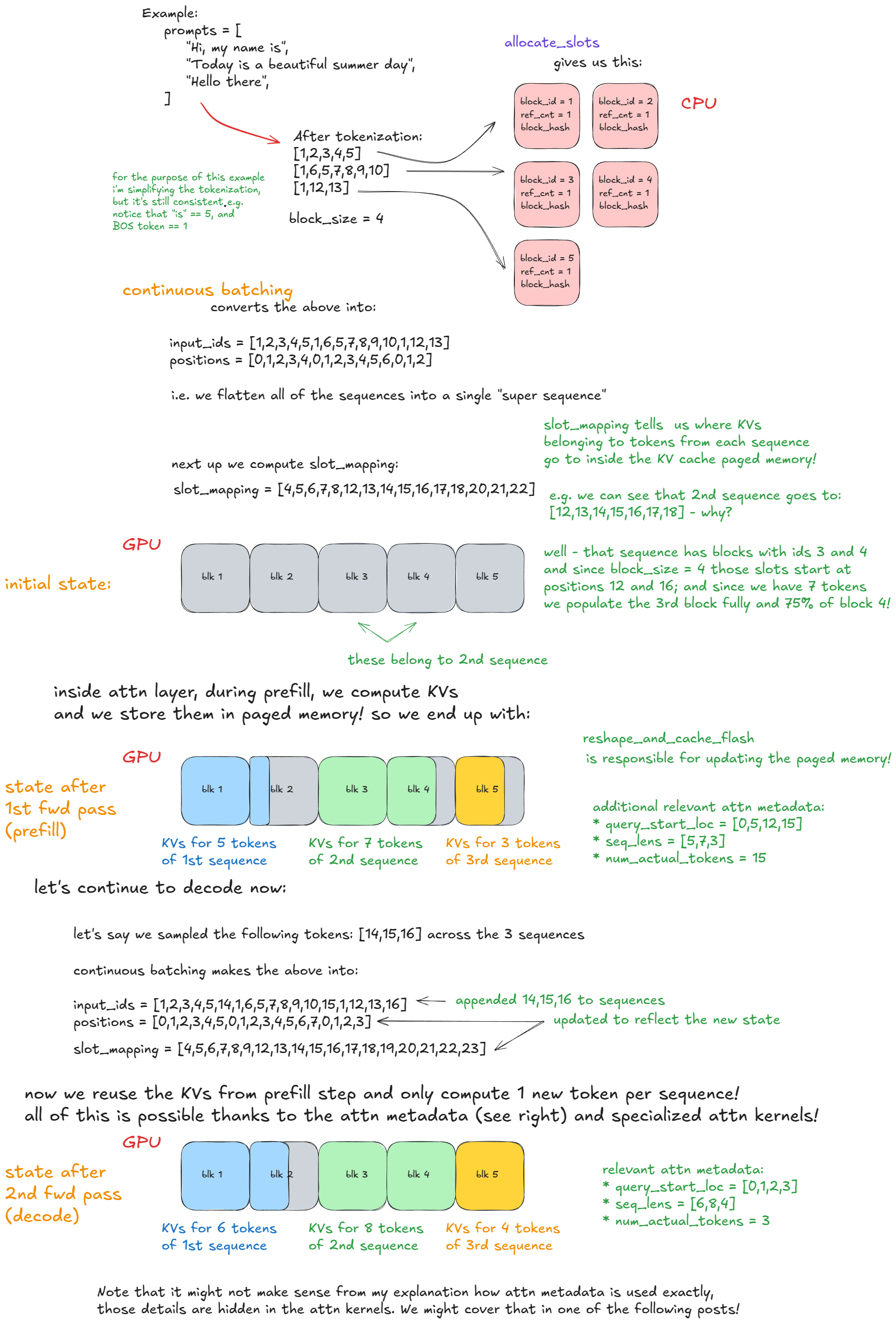
阶段 1:Prefill(处理用户输入,第一次计算 KV Cache)
输入准备
图里有 3 个用户请求:
Hi, my name is(token 化后是[1,2,3,4,5],长度 5)Today is a beautiful summer day(token 化后是[1,6,5,7,8,9,10],长度 7)Hello there(token 化后是[1,12,13],长度 3)
Continuous Batching 第一步:把所有请求 “拍扁” 成一个超级序列
把 3 个序列的
input_ids和positions(位置编码)拼起来,变成:input_ids = [1,2,3,4,5, 1,6,5,7,8,9,10, 1,12,13] positions = [0,1,2,3,4, 0,1,2,3,4,5,6, 0,1,2]这样,3 个请求的输入就被当成一个大序列处理,GPU 只需要跑一次前向传播,就能算出所有 token 的 KV Cache。
关键:KV Cache 用 “分页内存” 管理(PagedAttention)
vLLM 给 KV Cache 用了和操作系统虚拟内存一样的思路:
- 把显存分成一个个固定大小的 “块(block)”,图里
block_size=4,每个块能存 4 个 token 的 KV 数据; - 每个块有
block_id,还有ref_cnt(引用计数,记录有多少请求在用这个块); - 用
slot_mapping记录每个 token 的 KV 数据存在哪个块的哪个位置。
比如图里的
slot_mapping = [4,5,6,7,8,12,13,14,15,16,17,18,20,21,22],它告诉模型:- 第 2 个请求(长度 7)的 token,KV 数据存在块 3、块 4 里(块 3 存前 4 个,块 4 存后 3 个);
- 模型不用关心块的物理地址,只需要按
slot_mapping就能读写 KV Cache。
- 把显存分成一个个固定大小的 “块(block)”,图里
Prefill 结果:KV Cache 写入显存
跑完 Prefill 后,3 个请求的 KV Cache 都被写入了分页显存:
- 块 1、块 2 存了第 1 个请求的 5 个 token;
- 块 3、块 4 存了第 2 个请求的 7 个 token;
- 块 5 存了第 3 个请求的 3 个 token。
阶段 2:Decode(生成下一个 token,复用 KV Cache)
Prefill 完成后,每个请求都要生成下一个 token,这就是 Decode 阶段,也是 Continuous Batching 的精髓所在。
新 token 的 “拍扁”
假设 3 个请求分别采样出了新 token
[14,15,16],Continuous Batching 会把它们拼到原来的序列后面:input_ids = [1,2,3,4,5,14, 1,6,5,7,8,9,10,15, 1,12,13,16] positions = [0,1,2,3,4,5, 0,1,2,3,4,5,6,7, 0,1,2,3]同时更新
slot_mapping,给新 token 分配显存位置。复用 KV Cache,只算新 token
这里就是 vLLM 省时间的关键:
- 模型不用重新计算前面所有 token 的 KV,直接通过
slot_mapping读取 Prefill 阶段存好的 KV Cache; - 只需要计算新生成的 3 个 token 的 KV 数据,然后更新到显存里;
- 注意力内核会根据
query_start_loc、seq_lens这些元数据,知道每个请求的起始位置和长度,正确计算注意力,不会把不同请求的 token 混在一起。
- 模型不用重新计算前面所有 token 的 KV,直接通过
显存更新
跑完 Decode 后,显存里的 KV Cache 被更新:
- 第 1 个请求现在有 6 个 token,块 2 里又存了 1 个;
- 第 2 个请求有 8 个 token,块 4 里又存了 1 个;
- 第 3 个请求有 4 个 token,块 5 里又存了 1 个。
如果有序列已经完成推理,则可以将该序列的信息收集,然后将其所占用的资源及时释放。
3.补充:计算限制和内存限制
第1节有提到,prefill阶段是计算限制,compute-bound,到了decode阶段是内存限制 memory-bandwidth-bound。另外再不少文章中也有提到,Transform结构的计算瓶颈也属于memory-bound。如何确定一个网络结构或者计算阶段属于计算限制还是内存限制?
为了解答这个问题,我们先来看几个重要概念:
- 硬件算力上限。指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是 FLOPS or FLOP/s。
- 𝛽 :硬件带宽上限。指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。
- 𝜋𝑡 :某个算法所需的总运算量,单位是FLOPs。下标 𝑡 表示total。
- 𝛽𝑡 :某个算法所需的总数据读取存储量,单位是Byte。下标 𝑡 表示total。
这里再强调一下对FLOPS和FLOPs的解释:
- FLOPS:等同于FLOP/s,表示Floating Point Operations Per Second,即每秒执行的浮点数操作次数,用于衡量硬件计算性能。
- FLOPs:表示Floating Point Operations,表示某个算法的总计算量(即总浮点运算次数),用于衡量一个算法的复杂度。
我们知道,在执行运算的过程中,时间不仅花在计算本身上,也花在数据读取存储上,所以现在我们定义
- \(T_{cal}\):对某个算法而言,计算所耗费的时间,单位为s,下标cal表示calculate。其满足 \(𝑇_{𝑐𝑎𝑙}=\frac{𝜋_𝑡}{𝜋}\)
- \(𝑇_{𝑙𝑜𝑎𝑑}\) :对某个算法而言,读取存储数据所耗费的时间,单位为s。其满足 \(𝑇_{𝑙𝑜𝑎𝑑}=\frac{𝛽𝑡}{𝛽}\)
我们知道,数据在读取的同时,可以计算;在计算的同时也可以读取,所以我们有:
- \(T\) :对某个算法而言,完成整个计算所耗费的总时间,单位为s。其满足\(𝑇=𝑚𝑎𝑥(𝑇_{𝑐𝑎𝑙},𝑇_{𝑙𝑜𝑎𝑑})\)
也就是说,最终一个算法运行的总时间,取决于计算时间和数据读取时间中的最大值。
3.1 计算限制
当 \(𝑇_{𝑐𝑎𝑙}>𝑇_{𝑙𝑜𝑎𝑑}\) 时,算法运行的瓶颈在计算上,我们称这种情况为计算限制(math-bound)。此时我们有: \(\frac{𝜋_𝑡}{𝜋} > \frac{𝛽_𝑡}{𝛽}\) ,即 \(\frac{𝜋_𝑡}{𝛽_𝑡}>\frac𝜋𝛽\)
3.2 内存限制
当 \(𝑇_{𝑐𝑎𝑙}<𝑇_{𝑙𝑜𝑎𝑑}\) 时,算法运行的瓶颈在数据读取上,我们称这种情况为内存限制(memory-bound)。此时我们\(\frac{𝜋_𝑡}{𝜋} < \frac{𝛽_𝑡}{𝛽}\) ,即 \(\frac{𝜋_𝑡}{𝛽_𝑡}<\frac𝜋𝛽\)
我们称 \(\frac{𝜋_𝑡}{𝛽_𝑡}\) 为算法的计算强度(Operational Intensity)
4.参考
- (24 封私信 / 2 条消息) 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑 - 知乎
[vLLM 内部:高通量 LLM 推理系统的剖析 vLLM 博客 — Inside vLLM: Anatomy of a High-Throughput LLM Inference System vLLM Blog](https://vllm.ai/blog/anatomy-of-vllm) - (24 封私信 / 4 条消息) 叶泊秦淮 - 知乎 (zhihu.com)
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2026/04/19/Continuous-batching/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)