KVCache必知必会
大模型推理过程中,KVCache是非常重要的概念,对于KVCache的理解和工程上的处理也成为推理环节的重中之重。本文重在。介绍KVCache的由来和相关基础背景,以便更好地理解大模型推理中对于KVCache的工程处理。
1.为什么需要KVCache?
要回答这个问题,首先我们应该对transform结构有一定的基础了解。我在过往的文章里也有转载《Transformer核心架构解析》,这里不再赘述。这里贴上游凯超大神的推导过程,对于我自己来说,帮助我更加基础且深入的对KVCache进行理解。
对于LLM类模型的一次推理(生成一个token)的过程,我们可以将这个过程分解为下列过程:
输入n个token \(\{ T_1, ..., T_i, ..., T_n \}\),每个token就是一个整数
token预处理阶段,将token处理成token embedding\({x_1^0,⋯,x_i^0,⋯,x_n^0}\),每个token embedding就是一个向量,维度记为D。这里的上标0表示第0层,也就是输入,后面会用到。
token embedding变换阶段,模型内部包含L层,每层的输入是token embedding,输出也是token embedding。最后一层输出的token embedding是\(\{x_1^L,···,x_i^L,···,x_n^L\}\)
next token generation阶段,由最后一层的最后一个token embedding \(x_n^L\),结合vocabulary embedding (一般也叫
lm_head)\(\{e_1,⋯,e_i,⋯,e_V\}\),生成每个token的概率\(\{p_1,⋯,p_i,⋯,p_V\}\),再从这个概率分布中采样得到一个具体的token \(T_{n+1}\)。用一个流程图来表示,就是:
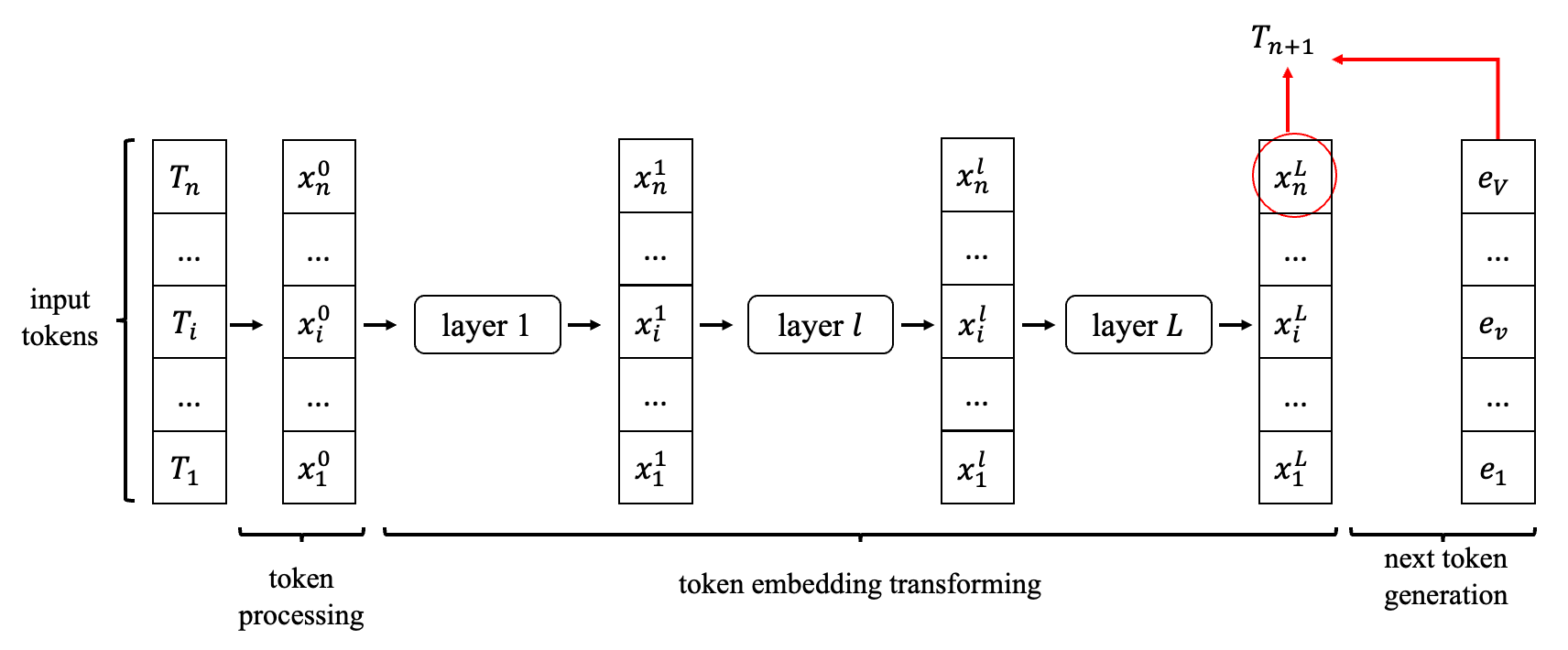
当我们已经生成了一个token(即\(T_{n+1}\)),需要生成下一个token(即\(T_{n+2}\))时,我们可以再走一遍上述流程。然而,聪明的算法工程师发现这两次生成的计算之间存在可以复用的部分:当输入token序列为\(\{ T_1, ..., T_i, ..., T_n, T_{n+1} \}\)时,$${x_i^l 1≤i≤n,1≤l≤L}\(与输入token序列为\) { T_1, …, T_i, …, T_n }$$ 的时候计算得到的结果是一样的,所以我们可以复用上一次计算的结果。
另外KVCache的存储大小及设计细节可以具体参考这篇文章。
2.KVCache的存储及实现细节
依据文章中的第二小节关于KVCache的原理和设计细节的推算,KVCache的总大小为\(2ndLH=2nDL\),正比于当前token数量、向量维度、层数。这里面,最令人头疼的是n,它是在推理过程中不断变大的一个量。变长数据的存储总是很烦人的,具体解决起来无外乎三种方法:
- 分配一个最大容量的缓冲区,要求提前预知最大的token数量。而且现在大模型卷得厉害,动不动支持上百万长度,而大部分的用户请求都很短。因此,按照最大容量来分配是非常浪费的。
- 动态分配缓冲区大小,类似经典的vector append的处理方式,超过容量了就扩增一倍。这也是一种可行的解决方案,但是(在GPU设备上)频繁申请、释放内存的开销很大,效率不高。
- 把数据拆散,按最小单元存储,用一份元数据记录每一块数据的位置。
最后一种方案,就是目前采用最多的方案,也叫PageAttention。程序在初始化时申请一整块显存(例如4GB),按照KVCache的大小划分成一个一个的小块,并记录每个token在推理时要用到第几个小块。小块显存的申请、释放、管理,类似操作系统对物理内存的虚拟化过程,这就是大名鼎鼎的vLLM的思路。
3.参考
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2026/04/15/KV-Cache-about/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)