背景
最近项目稳定性测试,出现了一个诡异的问题,在排除了内存泄漏问题以后,进程仍然有大量内存无法释放,通过查阅资料和实际测试最终得以解决,在此记录说明。
问题分析
问题的根本原因,在这篇文章中已经详细说明,并且也有源码相关分析,不再赘述。
其根本原因是 STL和glibc出现了伪“内存泄漏”, 项目中使用了大量的STL的std::vector作为中间缓存,数量多且内存块很小,这一点可以通过一下命令行查看:
ps -o majflt,minflt -p pid
发现majflt每秒增量为0,而minflt每秒增量大于10000。majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。 这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
这些小的中间缓存无法得到及时的释放,原因在于glibc底层内存申请的实现ptmalloc2。ptmalloc2 内存池的 fast bins 快速缓存和 top chunk 内存返还系统的特点导致。
具体的分析可以参考文章。
问题解决
最终是在项目频繁使用小内存块std::vector作为缓存的地方加上了malloc_trim(0)得以解决。以下是手册上malloc_trim的说明:
NAME
malloc_trim - release free memory from the top of the heap
SYNOPSIS
#include <malloc.h>
void malloc_trim(size_t pad);
DESCRIPTION
The malloc_trim() function attempts to release free memory at the top of the heap (by calling sbrk(2)
with a suitable argument).
The pad argument specifies the amount of free space to leave untrimmed at the top of the heap. If this
argument is 0, only the minimum amount of memory is maintained at the top of the heap (i.e., one page
or less). A nonzero argument can be used to maintain some trailing space at the top of the heap in
order to allow future allocations to be made without having to extend the heap with sbrk(2).
RETURN VALUE
The malloc_trim() function returns 1 if memory was actually released back to the system, or 0 if it was
not possible to release any memory.
malloc_trim只能释放堆上的空闲内存。
如何避免这类伪“内存泄漏”的问题?可以从以下几个方面入手:
- 避免内存泄漏。malloc/new 出来的内存,一定要 free/delete 掉。
- 避免分阶段分配内存,后面分配的内存,长期驻留在程序不释放。
- 可以考虑定时执行 malloc_trim(0) 强制回收整理 fast bins 小空闲内存块,释放物理内存。
- 考虑使用 jemalloc 和 tcmalloc 替换 ptmalloc。
代码示例说明
将问题抽象到比较小的代码示例中如下:
#include <string>
#include <string.h>
#include <unistd.h>
#include <iostream>
#include <list>
#include <malloc.h>
void print_mem_info(const char* s) {
printf("------------------------\n");
printf("-- %s\n", s);
printf("------------------------\n");
malloc_stats();
}
int main(int argc, char** argv) {
int cnt = atoi(argv[1]);
std::list<char*> free_list;
print_mem_info("begin");
for (int i = 0; i < cnt; i++) {
char* m = new char[1024 * 64];
memset(m, 'a', 1024 * 64);
free_list.push_back(m);
}
print_mem_info("alloc blocks");
for (auto& v : free_list) {
delete[] v;
}
print_mem_info("free blocks");
free_list.clear();
print_mem_info("clear list");
for (;;) {
sleep(1);
}
return 0;
}
输出结果为:
------------------------
-- begin
------------------------
Arena 0:
system bytes = 135168
in use bytes = 74352
Total (incl. mmap):
system bytes = 135168
in use bytes = 74352
max mmap regions = 0
max mmap bytes = 0
------------------------
-- alloc blocks
------------------------
Arena 0:
system bytes = 655982592
in use bytes = 655914352
Total (incl. mmap):
system bytes = 655982592
in use bytes = 655914352
max mmap regions = 0
max mmap bytes = 0
------------------------
-- free blocks
------------------------
Arena 0:
system bytes = 655982592
in use bytes = 394352
Total (incl. mmap):
system bytes = 655982592
in use bytes = 394352
max mmap regions = 0
max mmap bytes = 0
------------------------
-- clear list.
------------------------
Arena 0:
system bytes = 655982592
in use bytes = 74576
Total (incl. mmap):
system bytes = 655982592
in use bytes = 74576
max mmap regions = 0
max mmap bytes = 0
其中system bytes为malloc申请的总内存,in use bytes 则为正在使用的分配所消耗的字节总数。
可以看到最后在clear list之后,in use bytes已经恢复到程序刚启动时的状态(begin),但是system bytes的占用还是很大。
在程序结束之前使用malloc_trim(0):
#include <string>
#include <string.h>
#include <unistd.h>
#include <iostream>
#include <list>
#include <malloc.h>
void print_mem_info(const char* s) {
printf("------------------------\n");
printf("-- %s\n", s);
printf("------------------------\n");
malloc_stats();
}
int main(int argc, char** argv) {
int cnt = atoi(argv[1]);
std::list<char*> free_list;
print_mem_info("begin");
for (int i = 0; i < cnt; i++) {
char* m = new char[1024 * 64];
memset(m, 'a', 1024 * 64);
free_list.push_back(m);
}
print_mem_info("alloc blocks");
for (auto& v : free_list) {
delete[] v;
}
print_mem_info("free blocks");
free_list.clear();
print_mem_info("clear list");
malloc_trim(0);
print_mem_info("after trim");
for (;;) {
sleep(1);
}
return 0;
}
输出结果:
------------------------
-- begin
------------------------
Arena 0:
system bytes = 135168
in use bytes = 74352
Total (incl. mmap):
system bytes = 135168
in use bytes = 74352
max mmap regions = 0
max mmap bytes = 0
------------------------
-- alloc blocks
------------------------
Arena 0:
system bytes = 655982592
in use bytes = 655914352
Total (incl. mmap):
system bytes = 655982592
in use bytes = 655914352
max mmap regions = 0
max mmap bytes = 0
------------------------
-- free blocks
------------------------
Arena 0:
system bytes = 655982592
in use bytes = 394352
Total (incl. mmap):
system bytes = 655982592
in use bytes = 394352
max mmap regions = 0
max mmap bytes = 0
------------------------
-- clear list
------------------------
Arena 0:
system bytes = 655982592
in use bytes = 74576
Total (incl. mmap):
system bytes = 655982592
in use bytes = 74576
max mmap regions = 0
max mmap bytes = 0
------------------------
-- after trim
------------------------
Arena 0:
system bytes = 536576
in use bytes = 74576
Total (incl. mmap):
system bytes = 536576
in use bytes = 74576
max mmap regions = 0
max mmap bytes = 0
可以看出在after trim之后,system bytes占用明显减小。
补充说明
在极客时间陶辉老师的《系统性能调优必知必会》第2节–内存池:如何提升内存分配的效率?也对这个问题有相关介绍,其中还有使用 tcmalloc 替换 ptmalloc的方法,在此引用并补充说明。
以下是部分原文引用:
隐藏的内存池
实际上,在你的业务代码与系统内核间,往往有两层内存池容易被忽略,尤其是其中的 C 库内存池。
当代码申请内存时,首先会到达应用层内存池,如果应用层内存池有足够的可用内存,就会直接返回给业务代码,否则,它会向更底层的 C 库内存池申请内存。比如,如果你在 Apache、Nginx 等服务之上做模块开发,这些服务中就有独立的内存池。当然,Java 中也有内存池,当通过启动参数 Xmx 指定 JVM 的堆内存为 8GB 时,就设定了 JVM 堆内存池的大小。
你可能听说过 Google 的 TCMalloc 和 FaceBook 的 JEMalloc,它们也是 C 库内存池。当 C 库内存池无法满足内存申请时,才会向操作系统内核申请分配内存。如下图所示:
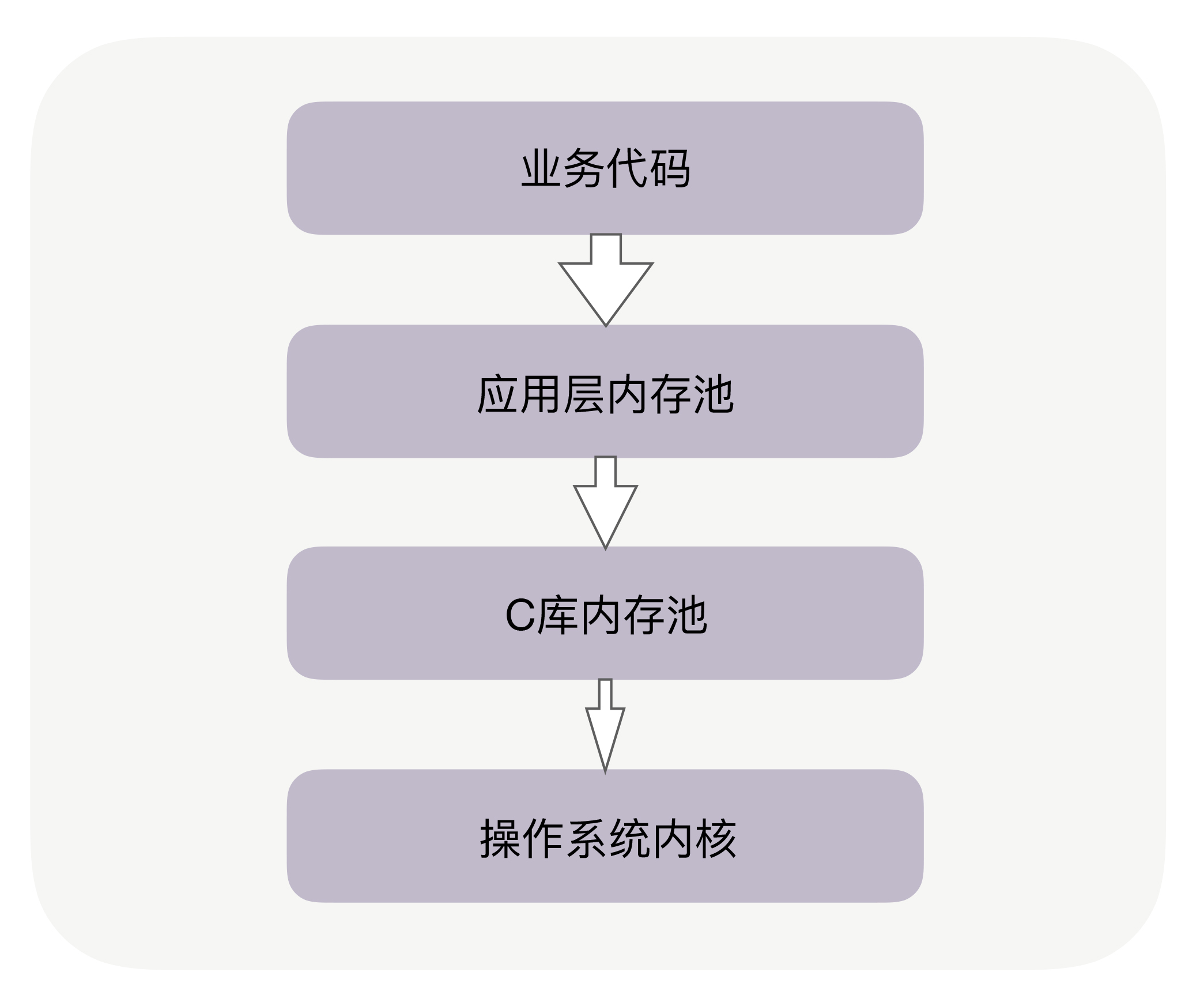
回到文章开头的问题,Java 已经有了应用层内存池,为什么还会受到 C 库内存池的影响呢?这是因为,除了 JVM 负责管理的堆内存外,Java 还拥有一些堆外内存,由于它不使用 JVM 的垃圾回收机制,所以更稳定、持久,处理 IO 的速度也更快。这些堆外内存就会由 C 库内存池负责分配,这是 Java 受到 C 库内存池影响的原因。
其实不只是 Java,几乎所有程序都在使用 C 库内存池分配出的内存。C 库内存池影响着系统下依赖它的所有进程。我们就以 Linux 系统的默认 C 库内存池 Ptmalloc2 来具体分析,看看它到底对性能发挥着怎样的作用。
C 库内存池工作时,会预分配比你申请的字节数更大的空间作为内存池。比如说,当主进程下申请 1 字节的内存时,Ptmalloc2 会预分配 132K 字节的内存(Ptmalloc2 中叫 Main Arena),应用代码再申请内存时,会从这已经申请到的 132KB 中继续分配。
如下所示(你可以在这里找到示例程序,注意地址的单位是 16 进制):
# cat /proc/2891/maps | grep heap
01643000-01664000 rw-p 00000000 00:00 0 [heap]
当我们释放这 1 字节时,Ptmalloc2 也不会把内存归还给操作系统。Ptmalloc2 认为,与其把这 1 字节释放给操作系统,不如先缓存着放进内存池里,仍然当作用户态内存留下来,进程再次申请 1 字节的内存时就可以直接复用,这样速度快了很多。
你可能会想,132KB 不多呀?为什么这一讲开头提到的 Java 进程,会被分配了几个 GB 的内存池呢?这是因为多线程与单线程的预分配策略并不相同。
每个子线程预分配的内存是 64MB(Ptmalloc2 中被称为 Thread Arena,32 位系统下为 1MB,64 位系统下为 64MB)。如果有 100 个线程,就将有 6GB 的内存都会被内存池占用。当然,并不是设置了 1000 个线程,就会预分配 60GB 的内存,子线程内存池最多只能到 8 倍的 CPU 核数,比如在 32 核的服务器上,最多只会有 256 个子线程内存池,但这也非常夸张了,16GB(64MB * 256 = 16GB)的内存将一直被 Ptmalloc2 占用。
回到本文开头的问题,Linux 下的 JVM 编译时默认使用了 Ptmalloc2 内存池,因此每个线程都预分配了 64MB 的内存,这造成含有上百个 Java 线程的 JVM 多使用了 6GB 的内存。在多数情况下,这些预分配出来的内存池,可以提升后续内存分配的性能。
然而,Java 中的 JVM 内存池已经管理了绝大部分内存,确实不能接受莫名多出来 6GB 的内存,那该怎么办呢?既然我们知道了 Ptmalloc2 内存池的存在,就有两种解决办法。首先可以调整 Ptmalloc2 的工作方式。通过设置 MALLOC_ARENA_MAX 环境变量,可以限制线程内存池的最大数量,当然,线程内存池的数量减少后,会影响 Ptmalloc2 分配内存的速度。不过由于 Java 主要使用 JVM 内存池来管理对象,这点影响并不重要。
其次可以更换掉 Ptmalloc2 内存池,选择一个预分配内存更少的内存池,比如 Google 的 TCMalloc。
这并不是说 Google 出品的 TCMalloc 性能更好,而是在特定的场景中的选择不同。而且,盲目地选择 TCMalloc 很可能会降低性能,否则 Linux 系统早把默认的内存池改为 TCMalloc 了。TCMalloc 和 Ptmalloc2 是目前最主流的两个内存池,接下来我带你通过对比 TCMalloc 与 Ptmalloc2 内存池,看看到底该如何选择内存池。
选择 Ptmalloc2 还是 TCMalloc?
先来看 TCMalloc 适用的场景,它对多线程下小内存的分配特别友好。
比如,在 2GHz 的 CPU 上分配、释放 256K 字节的内存,Ptmalloc2 耗时 32 纳秒,而 TCMalloc 仅耗时 10 纳秒(测试代码参见这里)。差距超过了 3 倍,为什么呢?这是因为,Ptmalloc2 假定,如果线程 A 申请并释放了的内存,线程 B 可能也会申请类似的内存,所以它允许内存池在线程间复用以提升性能。
因此,每次分配内存,Ptmalloc2 一定要加锁,才能解决共享资源的互斥问题。然而,加锁的消耗并不小。如果你监控分配速度的话,会发现单线程服务调整为 100 个线程,Ptmalloc2 申请内存的速度会变慢 10 倍。TCMalloc 针对小内存做了很多优化,每个线程独立分配内存,无须加锁,所以速度更快!
而且,线程数越多,Ptmalloc2 出现锁竞争的概率就越高。比如我们用 40 个线程做同样的测试,TCMalloc 只是从 10 纳秒上升到 25 纳秒,只增长了 1.5 倍,而 Ptmalloc2 则从 32 纳秒上升到 137 纳秒,增长了 3 倍以上。
下图是 TCMalloc 作者给出的性能测试数据,可以看到线程数越多,二者的速度差距越大。所以,当应用场景涉及大量的并发线程时,换成 TCMalloc 库也更有优势!
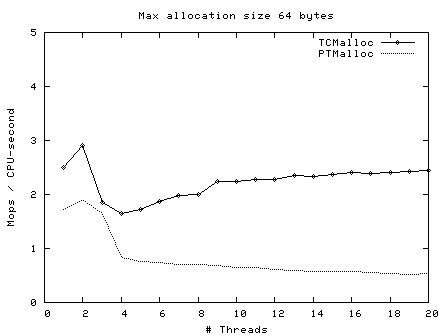
那么,为什么 GlibC 不把默认的 Ptmalloc2 内存池换成 TCMalloc 呢?因为 Ptmalloc2 更擅长大内存的分配。
比如,单线程下分配 257K 字节的内存,Ptmalloc2 的耗时不变仍然是 32 纳秒,但 TCMalloc 就由 10 纳秒上升到 64 纳秒,增长了 5 倍以上!现在 TCMalloc 反过来比 Ptmalloc2 慢了 1 倍!这是因为 TCMalloc 特意针对小内存做了优化。
多少字节叫小内存呢?TCMalloc 把内存分为 3 个档次,小于等于 256KB 的称为小内存,从 256KB 到 1M 称为中等内存,大于 1MB 的叫做大内存。TCMalloc 对中等内存、大内存的分配速度很慢,比如我们用单线程分配 2M 的内存,Ptmalloc2 耗时仍然稳定在 32 纳秒,但 TCMalloc 已经上升到 86 纳秒,增长了 7 倍以上。
所以,如果主要分配 256KB 以下的内存,特别是在多线程环境下,应当选择 TCMalloc;否则应使用 Ptmalloc2,它的通用性更好。
从堆还是栈上分配内存?
不知道你发现没有,刚刚讨论的内存池中分配出的都是堆内存,如果你把在堆中分配的对象改为在栈上分配,速度还会再快上 1 倍(具体测试代码可以在这里找到)!为什么?
可能有同学还不清楚堆和栈内存是如何分配的,我先简单介绍一下。
如果你使用的是静态类型语言,那么,不使用 new 关键字分配的对象大都是在栈中的。比如:
C/C++/Java语言:int a = 10;
否则,通过 new 或者 malloc 关键字分配的对象则是在堆中的:
C语言:int * a = (int*) malloc(sizeof(int));
C++语言:int * a = new int;
Java语言:int a = new Integer(10);
另外,对于动态类型语言,无论是否使用 new 关键字,内存都是从堆中分配的。
了解了这一点之后,我们再来看看,为什么从栈中分配内存会更快。
这是因为,由于每个线程都有独立的栈,所以分配内存时不需要加锁保护,而且栈上对象的尺寸在编译阶段就已经写入可执行文件了,执行效率更高!性能至上的 Golang 语言就是按照这个逻辑设计的,即使你用 new 关键字分配了堆内存,但编译器如果认为在栈中分配不影响功能语义时,会自动改为在栈中分配。
当然,在栈中分配内存也有缺点,它有功能上的限制。一是, 栈内存生命周期有限,它会随着函数调用结束后自动释放,在堆中分配的内存,并不随着分配时所在函数调用的结束而释放,它的生命周期足够使用。二是,栈的容量有限,如 CentOS 7 中是 8MB 字节,如果你申请的内存超过限制会造成栈溢出错误(比如,递归函数调用很容易造成这种问题),而堆则没有容量限制。
所以,当我们分配内存时,如果在满足功能的情况下,可以在栈中分配的话,就选择栈。
更换合适的内存池
即使对第三方组件,我们也可以通过 LD_PRELOAD 环境变量,在程序启动时更换最适合的 C 库内存池(Linux 中通过 LD_PRELOAD 修改动态库来更换内存池,参见示例代码)。
对比测试tcmalloc与ptmalloc2的性能
//benchmark.cpp
#include "stdio.h"
#include <stdlib.h>
#include <sys/time.h>
#include <unistd.h>
#include <pthread.h>
int TESTN = 128*1024*1024;
int size = 64;
void* loopalloc(void* args) {
timeval tStart,tEnd;
void* addr;
//这里不再使用clock,因为clock表示的进程所占用过的CPU周期,它将所有CPU都计入了,不适合示例中的统计
gettimeofday(&tStart, 0);
for (int i = 0; i < TESTN; i++) {
addr = malloc(size);
free(addr);
}
gettimeofday(&tEnd, 0);
//将消耗时间传出到timecost数组中对应的元素上
*(long*)args = (1000000LL * (tEnd.tv_sec-tStart.tv_sec) + (tEnd.tv_usec-tStart.tv_usec));
}
int main(int argc, char** argv) {
int threadnum = 1;
int ch;
while((ch = getopt(argc, argv, "t:s:n:")) != -1) {
switch(ch)
{
//设置测试的并发线程数,注意不要超过机器上的CPU核数
case 't':
threadnum = atoi(optarg);
break;
//指定分配内存块的大小
case 's':
size = atoi(optarg);
break;
//循环次数
case 'n':
TESTN = atoi(optarg);
break;
}
}
//统计每个线程计算所需要的时间
long* timecost = new long[threadnum];
long costsum = 0;
if (1 == threadnum) {
loopalloc(&costsum);
} else {
pthread_t* id = new pthread_t[threadnum];
for(int i = 0; i < threadnum; i++) {
int ret=pthread_create(&id[i],NULL,loopalloc,&timecost[i]);
if(ret!=0){
printf("Create pthread error!\n");
exit (1);
}
}
//等待所有线程结束
for(int i = 0; i < threadnum; i++) {
pthread_join(id[i],NULL);
costsum += timecost[i];
}
}
//比较平均每线程所用时间
printf("%d线程 %d字节: %.2f纳秒\n", threadnum,size,(double)costsum/threadnum/TESTN*1000);
}
编译:
g++ benchmark.cpp -o benchmark -lpthread
基于ptmalloc2测试
单线程分配256KB
export LD_PRELOAD=””; ./benchmark -s 262144 -t 1
2线程分配256KB
export LD_PRELOAD=””; ./benchmark -s 262144 -t 2
40线程分配256KB
export LD_PRELOAD=””; ./benchmark -s 262144 -t 40
单线程分配256KB+1字节
export LD_PRELOAD=””; ./benchmark -s 262145 -t 1
10线程分配256KB+1字节
export LD_PRELOAD=””; ./benchmark -s 262145 -t 10
基于TcMalloc测试
根据configure生成的libtcmalloc.so文件的位置填写LD_PRELOAD
单线程分配256KB
export LD_PRELOAD=”/lib64/libtcmalloc.so”; ./benchmark -s 262144 -t 1
2线程分配256KB
export LD_PRELOAD=”/lib64/libtcmalloc.so”; ./benchmark -s 262144 -t 2
40线程分配256KB
export LD_PRELOAD=”/lib64/libtcmalloc.so”; ./benchmark -s 262144 -t 40
单线程分配256KB+1字节
export LD_PRELOAD=”/lib64/libtcmalloc.so”; ./benchmark -s 262145 -t 1
10线程分配256KB+1字节
export LD_PRELOAD=”/lib64/libtcmalloc.so”; ./benchmark -s 262145 -t 10 -n 100000
参考
- https://zhuanlan.zhihu.com/p/452291093
- https://zhuanlan.zhihu.com/p/498067223
- https://www.cnblogs.com/zhanggaofeng/p/15941542.html
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2023/06/06/memleak-about-STL-and-glic-deal-with-malloc_trim/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)