C++ 抽象建模类设计准则
类设计中需要关注的点
1.final
class Interface // 接口类定义,没有final,可以被继承
{ ... };
class Implement final : // 实现类,final禁止再被继承
public Interface // 只用public继承
{ ... };
C++11 新增了一个特殊的标识符“final”(注意,它不是关键字),把它用于类定义,就可以显式地禁用继承,防止其他人有意或者无意地产生派生类。无论是对人还是对编译器,效果都非常好,我建议你一定要积极使用。
另外final还可以用在声明成员函数,与之相关的是override描述符,标识虚函数重载的描述符。二者是多态下用来控制继承和派生的关键字。
2.不可复制的类
class Noncopyable
{
public:
Noncopyable(const Noncopyable&) = delete;
void operator=(const Noncopyable&) = delete;
protected:
Noncopyable() = default;
~Noncopyable() = default;
};
可以使用上述类作为基类,当子类继承Noncopyable后,由于无法拷贝基类,所以子类的拷贝构造和拷贝赋值函数也会被声明为delete。进而达到不可复制类的效果。
#include <iostream>
#include <memory>
class Noncopyable
{
public:
Noncopyable(const Noncopyable&) = delete;
void operator=(const Noncopyable&) = delete;
protected:
Noncopyable() = default;
~Noncopyable() = default;
};
class AA :public Noncopyable{
public:
AA()
{
}
~AA() {}
};
int main()
{
AA aa;
return 0;
}
可以通过C++ Insights进一步观察上述代码:
#include <iostream>
#include <memory>
class Noncopyable
{
public:
// inline Noncopyable(const Noncopyable &) = delete;
// inline void operator=(const Noncopyable &) = delete;
protected:
inline constexpr Noncopyable() noexcept = default;
inline ~Noncopyable() noexcept = default;
};
class AA : public Noncopyable
{
public:
inline AA()
: Noncopyable()
{
}
inline ~AA() noexcept
{
}
// inline AA(const AA &) /* noexcept */ = delete;
// inline AA & operator=(const AA &) /* noexcept */ = delete;
};
int main()
{
AA aa = AA();
auto bb = std::move(aa); //顺便说一句,由于没有声明移动构造和移动拷贝函数,会默认使用复制构造函数;又由于删除了复制构造函数,所以此句会报错。
return 0;
}
3.现代C++的六大基本函数
在现代 C++ 里,一个类总是会有六大基本函数:三个构造、两个赋值、一个析构。
- 默认构造函数
- 复制构造函数
- 复制赋值运算符
- 移动构造函数 (C++11)
- 移动赋值操作符 (C++11)
- 析构函数
自动生成特殊成员函数的规则:
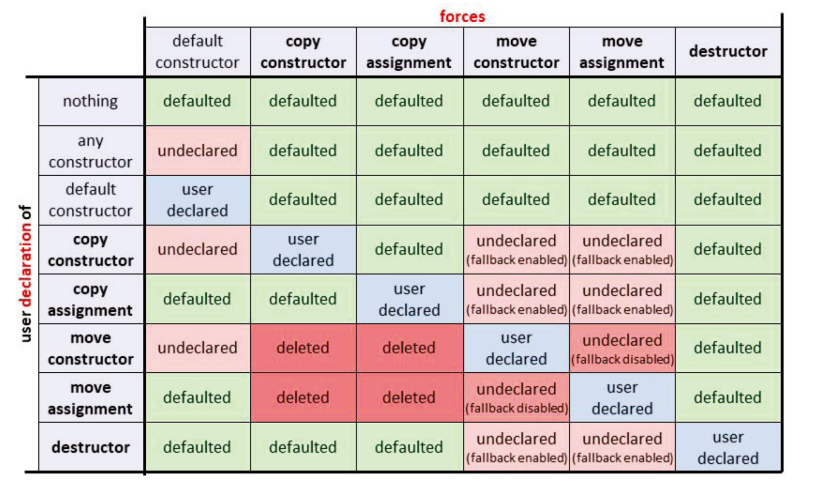
可以在这个表格中看到一些基本的规则 :
- 只有在没有用户声明其他构造函数的情况下,才会自动声明默认构造函数。
- 特殊的复制成员函数和析构函数禁用了移动支持。自动生成特殊的移动成员函数是禁用的 (除非也声明了移动操作)。但是,移动对象的请求通常是有效的,因为复制成员函数用作后备 (除非特殊的移动成员函数显式删除)。
- 特殊的移动成员函数禁用了正常的复制和赋值。复制和其他移动特殊成员函数将删除,这样只能移动 (分配) 对象,而不能复制 (分配) 对象 (除非还声明了其他操作)。
C++ 编译器会自动为我们生成这些函数的默认实现,省去我们重复编写的时间和精力。但我建议,对于比较重要的构造函数和析构函数,应该用“= default”的形式,明确地告诉编译器(和代码阅读者):“应该实现这个函数,但我不想自己写。”这样编译器就得到了明确的指示,可以做更好的优化。
class DemoClass final
{
public:
DemoClass() = default; // 明确告诉编译器,使用默认实现
~DemoClass() = default; // 明确告诉编译器,使用默认实现
};
这种“= default”是 C++11 新增的专门用于六大基本函数的用法,相似的,还有一种“= delete”的形式。它表示明确地禁用某个函数形式,而且不限于构造 / 析构,可以用于任何函数(成员函数、自由函数)。比如说,如果你想要禁止对象拷贝,就可以用这种语法显式地把拷贝构造和拷贝赋值“delete”掉,让外界无法调用。
class DemoClass final
{
public:
DemoClass(const DemoClass&) = delete; // 禁止拷贝构造
DemoClass& operator=(const DemoClass&) = delete; // 禁止拷贝赋值
};
经过笔者的测试,不同的编译器默认生成六大基本函数的规则不是很统一。CppCoreGuidelines指明,当这些特殊的成员函数(复制构造函数、移动构造函数、复制赋值操作符、移动赋值操作符或析构函数)其中某一个被实现或者使用了default或者deleted时,应该同时实现或者使用default或者deleted来处理其他四个特殊函数。
根据《C++ Move Semantics》3.4小节三五法则的建议总结:如果声明了复制构造函数、移动构造函数、复制赋值操作符、移动赋值操作符或析构函数,则必须仔细考虑如何处理其他特殊成员函数。
因为 C++ 有隐式构造和隐式转型的规则,如果你的类里有单参数的构造函数,或者是转型操作符函数,为了防止意外的类型转换,保证安全,就要使用“explicit”将这些函数标记为“显式”。
class DemoClass final
{
public:
explicit DemoClass(const string_type& str) // 显式单参构造函数
{ ... }
explicit operator bool() // 显式转型为bool
{ ... }
};
4.std::move语义和noexcept
通过代码示例来说明noexcept关键字。下面的类有一个string成员,并实现了复制和移动构造函数:
// basics/person.hpp
#include <string>
#include <iostream>
class Person {
private:
std::string name;
public:
Person(const char* n)
: name{n} {
std::cout << "CTOR " << name << '\n';
}
std::string getName() const {
return name;
}
// print out when we copy or move:
Person(const Person& p)
: name{p.name} {
std::cout << "COPY " << name << '\n';
}
Person(Person&& p)
: name{std::move(p.name)} {
std::cout << "MOVE " << name << '\n';
}
...
};
接下来创建并初始化一个Person的vector, 并插入person对象:
// basics/person.cpp
#include "person.hpp"
#include <iostream>
#include <vector>
int main()
{
std::vector<Person> coll {
"Wolfgang Amadeus Mozart",
"Johann Sebastian Bach",
"Ludwig van Beethoven"
};
std::cout << "capacity: " << coll.capacity() << '\n';
coll.push_back("Pjotr Iljitsch Tschaikowski");
}
输出打印为:
CTOR Wolfgang Amadeus Mozart
CTOR Johann Sebastian Bach
CTOR Ludwig van Beethoven
COPY Wolfgang Amadeus Mozart
COPY Johann Sebastian Bach
COPY Ludwig van Beethoven
capacity: 3
CTOR Pjotr Iljitsch Tschaikowski
MOVE Pjotr Iljitsch Tschaikowski
COPY Wolfgang Amadeus Mozart
COPY Johann Sebastian Bach
COPY Ludwig van Beethoven
简单解释以上过程,首先隐式转换生成三个Person对象,然后调用拷贝构造初始化了vector coll。当插入第四个元素时,会导致vector扩容,会将现有的内存复制到新内存中。操作结束后会释放旧元素的内存。这里有个问题,为什么vector不使用移动构造函数把旧元素的移动到新的内存中?
强异常安全保证
vector 的重新分配不使用移动语义的原因是, push_back() 提供了强异常处理保证: 在 vector 的重新分配过程中抛出异常时, C++ 标准库保证将 vector 回退到之前的状态。也就是说, push_back()提供了一种保证: 要么成功,要么无效 。
重新分配是使用移动语义的最优位置,因为只是元素从一个位置移动到另一个位置。因此,C++11 希望在这里使用移动语义。但是,如果在重新分配期间抛出异常,就无法回退了。新内存中的元素已经窃取了旧内存中元素的值。因此,只是销毁新的元素还不够,还得把他们移回去。但怎么知道把移回去的时候就不会失败呢?你可能会说一个移动构造函数永远不抛出异常。这可能是正确的字符串 (因为我们只是移动值和指针),而是需要对象在一个有效的状态,这种状态可能需要额外的内存,所以当额外内存有问题时会丢弃状态信息 (例如,基于节点的容器 Visual C++ 实现方式) 。
所以最终的决议是,只有当元素类型的移动构造函数保证不抛出异常时,才在重新分配时使用移动语义。
继续刚才的代码示例,现在使用noexcept来保证Person类的移动构造函数永远不会抛出异常:
// basics/personmove.hpp
#include <string>
#include <iostream>
class Person {
private:
std::string name;
public:
Person(const char* n)
: name{n} {
}
std::string getName() const {
return name;
}
// print out when we copy or move:
Person(const Person& p)
: name{p.name} {
std::cout << "COPY " << name << '\n';
}
Person(Person&& p) noexcept // guarantee not to throw
: name{std::move(p.name)} {
std::cout << "MOVE " << name << '\n';
}
...
};
还是同样的方式使用Person类:
#include "personmove.hpp"
#include <iostream>
#include <vector>
int main()
{
std::vector<Person> coll {
"Wolfgang Amadeus Mozart",
"Johann Sebastian Bach",
"Ludwig van Beethoven"
};
std::cout << "capacity: " << coll.capacity() << '\n';
coll.push_back("Pjotr Iljitsch Tschaikowski");
}
这次的输出为:
CTOR Wolfgang Amadeus Mozart
CTOR Johann Sebastian Bach
CTOR Ludwig van Beethoven
COPY Wolfgang Amadeus Mozart
COPY Johann Sebastian Bach
COPY Ludwig van Beethoven
capacity: 3
CTOR Pjotr Iljitsch Tschaikowski
MOVE Pjotr Iljitsch Tschaikowski
MOVE Wolfgang Amadeus Mozart
MOVE Johann Sebastian Bach
MOVE Ludwig van Beethoven
其余关于noexcept使用的细节可以查看《C++ Move Semantics》第7章,这里不再赘述。
5. const正确性
const正确性是指使用C++ const关键字将变量或者方法声明为不可变的,这是一种编译时结构,可以用来保证代码的正确性,使他不能修改某些变量。使用const正确性虽说只是良好的编程实践,但它也提供了能够表达方法意图的文档信息,从而使这些方法更佳易用。
5.1 函数方法的const正确性
const方法不能修改类的任何成员变量,本质上,const方法内的所有成员变量都被当做const变量。
例如getter函数、print函数等不改变类属性的函数,加上const属性,能够使代码意图更清晰。
// myobject.h
class MyObject {
public:
void PrintName() const;
std::string GetName() const;
private:
std::string mName;
};
6. C++标准属性特性
虽然从语法上来说属性可以出现在程序的任意位置, 但是从C++11到C++20标准一共只定义了9种标准属性。 这是因为C++标准委员会对于标准属性的定义非常谨慎。 一方面他们需要考虑一个语言特性应该定义为关键字还是定义为属性, 另一方面还需要谨慎考虑该属性是否是平台通用。 举例来说, 在标准属性确定之前对齐字节长度一直作为一个扩展属性出现在各种编译器中, 但是C++标准并不认可这种情况, 于是对齐字节长度作为语言本身的一部分出现在了新的标准当中。接下来就让我们看一看目前定义的9种标准属性。
- [[noreturn]] (C++11 起)
指示函数在完成后不会将控制流返回给调用函数(例如,终止应用程序、抛出异常、无限循环等函数)。
此属性仅应用到函数声明中正在声明的函数名。若拥有此属性的函数实际上返回,则行为未定义。
在C++标准库中 abort, exit, terminate等函数被声明为noreturn属性。
[[noreturn]] void f()
{
throw "error";
// OK
}
void q [[noreturn]] (int i)
{
// 如果使用参数 <= 0 调用,则行为未定义
if (i > 0)
throw "positive";
}
// void h() [[noreturn]]; // 错误:属性应用于 h 的函数类型,而不是 h 本身
int main()
{
try { f(); } catch(...) {}
try { q(42); } catch(...) {}
}
- [[carries_dependency]] (C++11 起)
carries_dependency是C++11标准引入的属性, 该属性允许跨函数传递内存依赖项, 它通常用于弱内存顺序架构平台上多线程程序的优化, 避免编译器生成不必要的内存栅栏指令。 所谓弱内存顺序架构, 简单来说是指在多核心的情况下, 一个核心看到共享内存中的值的变化与另一个核心写入它们的顺序不同。
该属性可以出现在两种情况中。
- 作为函数或者lambda表达式参数的属性出现, 这种情况表示调用者不用担心内存顺序, 函数内部会处理好这个问题, 编译器可以不生成内存栅栏指令。
- 作为函数的属性出现, 这种情况表示函数的返回值已经处理好内存顺序, 不需要编译器在函数返回前插入内存栅栏指令。
- [[deprecated]] (C++14起)
deprecated是在C++14标准中引入的属性, 带有此属性的实体被声明为弃用, 虽然在代码中依然可以使用它们, 但是并不鼓励这么做。当代码中出现带有弃用属性的实体时, 编译器通常会给出警告而不是错误 。
#include <iostream>
[[deprecated]] void foo() {}
class [[deprecated]] X {};
int main()
{
X x;
foo();
}
上述代码用例中编译器会报以下警告:
prog.cc: In function 'int main()':
prog.cc:8:7: warning: 'X' is deprecated [-Wdeprecated-declarations]
8 | X x;
| ^
prog.cc:4:22: note: declared here
4 | class [[deprecated]] X {};
| ^
prog.cc:9:8: warning: 'void foo()' is deprecated [-Wdeprecated-declarations]
9 | foo();
| ~~~^~
prog.cc:3:21: note: declared here
3 | [[deprecated]] void foo() {}
| ^~~
prog.cc:8:7: warning: unused variable 'x' [-Wunused-variable]
8 | X x;
| ^
另外deprecated属性还能接受一个参数用来指示弃用的具体原因或者提示用户使用新的函数, 比如:
#include <iostream>
[[deprecated("foo was deprecated, use bar instead")]] void foo() {}
class [[deprecated]] X {};
int main()
{
X x;
foo();
}
以上代码使用GCC编译时会给出常规的弃用警告,还会带上我们制定的字符串:
prog.cc: In function 'int main()':
prog.cc:8:7: warning: 'X' is deprecated [-Wdeprecated-declarations]
8 | X x;
| ^
prog.cc:4:22: note: declared here
4 | class [[deprecated]] X {};
| ^
prog.cc:9:8: warning: 'void foo()' is deprecated: foo was deprecated, use bar instead [-Wdeprecated-declarations]
9 | foo();
| ~~~^~
prog.cc:3:60: note: declared here
3 | [[deprecated("foo was deprecated, use bar instead")]] void foo() {}
| ^~~
prog.cc:8:7: warning: unused variable 'x' [-Wunused-variable]
8 | X x;
| ^
deprecated这个属性的使用范围非常广泛, 它不仅能用在类、 结构体和函数上, 在普通变量、 别名、 联合体、 枚举类型甚至命名空间上都可以使用 。
- [[fallthrough]] (C++17起)
fallthrough是C++17标准中引入的属性, 该属性可以在switch语句的上下文中提示编译器直落行为是有意的, 并不需要给出警告。直落语句只能用在 switch 语句中,其中待执行的下个语句是该 switch 语句的带 case 或 default 标号的语句。如果直落语句在循环中,那么下个(带标号)语句必须是该循环的同一迭代的一部分。 比如:
#include <iostream>
void bar() {}
void foo(int a)
{
switch (a)
{
case 0:
break;
case 1:
bar();
[[fallthrough]];
case 2:
bar();
break;
default:
break;
}
}
int main()
{
foo(1);
}
如果去掉case1中的fallthrough声明,则部分编译器会报警告:
prog.cc: In function 'void foo(int)':
prog.cc:10:12: warning: this statement may fall through [-Wimplicit-fallthrough=]
10 | bar();
| ~~~^~
prog.cc:12:5: note: here
12 | case 2:
- [[nodiscard]] (C++17起)
nodiscard是在C++17标准中引入的属性, 该属性声明函数的返回值不应该被舍弃, 否则鼓励编译器给出警告提示。 nodiscard属性也可以声明在类或者枚举类型上, 但是它对类或者枚举类型本身并不起作用, 只有当被声明为nodiscard属性的类或者枚举类型被当作函数返回值的时候才发挥作用:
在上面的代码中, 函数foo带有nodiscard属性, 所以在main函数中忽略foo函数的返回值会让编译器发出警告。 类X也被声明为nodiscard, 不过该属性对类本身没有任何影响, 编译器不会给出警告。 但是当类X作为bar函数的返回值时情况就不同了, 这时候相当于声明了函数[[nodiscard]] X bar()。 在main函数中, 忽略bar函数返回值的行为也会引发一个警告。
prog.cc: In function 'int main()':
prog.cc:9:8: warning: ignoring return value of 'int foo()', declared with attribute 'nodiscard' [-Wunused-result]
9 | foo();
| ~~~^~
prog.cc:3:19: note: declared here
3 | [[nodiscard]] int foo() { return 1; }
| ^~~
prog.cc:10:8: warning: ignoring returned value of type 'X', declared with attribute 'nodiscard' [-Wunused-result]
10 | bar();
| ~~~^~
prog.cc:4:3: note: in call to 'X bar()', declared here
4 | X bar() { return X(); };
| ^~~
prog.cc:2:21: note: 'X' declared here
2 | class [[nodiscard]] X {};
| ^
prog.cc:8:7: warning: unused variable 'x' [-Wunused-variable]
8 | X x;
| ^
需要注意的是, nodiscard属性只适用于返回值类型的函数, 对于返回引用的函数使用nodiscard属性是没有作用的:
class[[nodiscard]] X{};
X& bar(X &x) { return x; };
int main()
{
X x;
bar(x); // bar返回引用, nodiscard不起作用, 不会引发警告
}
nodiscard属性有几个常用的场合。 :
- 防止资源泄露, 对于像malloc或者new这样的函数或者运算符, 它们返回的内存指针是需要及时释放的, 可以使用nodiscard属性提示调用者不要忽略返回值。
- 对于工厂函数而言, 真正有意义的是回返的对象而不是工厂函数, 将nodiscard属性应用在工厂函数中也可以提示调用者别忘了使用对象, 否则程序什么也不会做。
- 对于返回值会影响程序运行流程的函数而言, nodiscard属性也是相当合适的, 它告诉调用方其返回值应该用于控制后续的流程。
从C++20标准开始, nodiscard属性支持将一个字符串字面量作为属性的参数, 该字符串会包含在警告中, 可以用于解释返回结果不应被忽略的理由:
[[nodiscard("Memory leak!")]] char* foo() { return new char[100]; }
- [[maybe_unused]] (C++17起)
maybe_unused是在C++17标准中引入的属性, 该属性声明实体可能不会被应用以消除编译器警告。
请注意, maybe_unused属性除作为函数形参属性外, 还可以用在很多地方, 比如类、 结构体、 联合类型、 枚举类型、 函数、 变量等, 读者可以根据具体情况对代码添加属性。
#include <cassert>
[[maybe_unused]] void f([[maybe_unused]] bool thing1,
[[maybe_unused]] bool thing2)
{
[[maybe_unused]] bool b = thing1 && thing2;
assert(b); // 发行模式中,assert 在编译中被去掉,因而未使用 b
// 无警告`,因为它被声明为 [[maybe_unused]]
} // 未使用参数 thing1 与 thing2,无警告
int main() {
}
- [[likely]] 和 [[unlikely]] (C++20起)
likely和unlikely是C++20标准引入的属性, 两个属性都是声明在标签或者语句上的。 其中likely属性允许编译器对该属性所在的执行路径相对于其他执行路径进行优化; 而unlikely属性恰恰相反。 通常, likely和unlikely被声明在switch语句:
#include <iostream>
int f(int i)
{
if (i < 0) [[unlikely]] {
return 0;
}
return 1;
}
int main()
{
std::cout << f(-1) << std::endl;
std::cout << f(1) << std::endl;
}
- [[no_unique_address]] (C++20起)
no_unique_address是C++20标准引入的属性, 该属性指示编译器该数据成员不需要唯一的地址, 也就是说它不需要与其他非静态数据成员使用不同的地址。 注意, 该属性声明的对象必须是非静态数据成员且不为位域 。
#include <iostream>
struct Empty {}; // 空类
struct X {
int i;
Empty e;
};
struct Y {
int i;
[[no_unique_address]] Empty e;
};
struct Z {
char c;
[[no_unique_address]] Empty e1, e2;
};
struct W {
char c[2];
[[no_unique_address]] Empty e1, e2;
};
int main()
{
// 任何空类类型对象的大小至少为 1
static_assert(sizeof(Empty) >= 1);
// 至少需要多一个字节以给 e 唯一地址
static_assert(sizeof(X) >= sizeof(int) + 1);
// 优化掉空成员
std::cout << "sizeof(Y) == sizeof(int) is " << std::boolalpha
<< (sizeof(Y) == sizeof(int)) << '\n';
// e1 与 e2 不能共享同一地址,因为它们拥有相同类型,尽管它们标记有 [[no_unique_address]]。
// 然而,其中一者可以与 c 共享地址。
static_assert(sizeof(Z) >= 2);
// e1 与 e2 不能拥有同一地址,但它们之一能与 c[0] 共享,而另一者与 c[1] 共享
std::cout << "sizeof(W) == 2 is " << (sizeof(W) == 2) << '\n';
}
可能得输出:
sizeof(Y) == sizeof(int) is true
sizeof(W) == 2 is true
最后解释一下no_unique_address这个属性的使用场景。 读者一定写过无状态的类, 这种类不需要有数据成员, 唯一需要做的就是实现一些必要的函数, 常见的是STL中一些算法函数所需的函数对象(仿函数) 。 而这种类作为数据成员加入其他类时, 会占据独一无二的内存地址, 实际上这是没有必要的。 所以, 在C++20的环境下, 我们可以使用no_unique_address属性, 让其不需要占用额外的内存地址空间 。
API类设计要点
1.降低类耦合
Scott Meyers建议,如果情况允许,那么优先声明非成员、非友元的函数,而非成员函数。这么做在促进封装的同时还降低了这些函数和类的耦合度。例如以下用例通过PrintName()成员函数将成员变量输出到标准输出。该方法使用共有的getter方法GetName()获取成员变量当前的值。
// myobject.h
class MyObject {
public:
void PrintName() const;
std::string GetName() const;
protected:
...
private:
std::string mName;
};
根据Scott Meyers的建议, 可以优先使用以下方式:
// myobject.h
class MyObject {
public:
std::string GetName() const;
protected:
...
private:
std::string mName;
};
void PrintName(const MyObject& obj);
后一种形式降低了耦合度,因为自由函数PrintName()只能访问MyObject的公有方法。如果是第一种成员函数的形式,PrintName()还可以访问类的私有和受保护的成员函数和成员变量。因此优先使用非成员、非友元的形式意味着不会与类内部的细节耦合。
另外该技巧也会促成最小完备的接口,因为类仅包含需要实现的最小功能,而基于公有接口实现的功能声明都在类的外部。值得一提的是,该技巧在STL中常见,例如std::for_each()和std::unique()算法都声明在容器类之外。
2.Pimpl惯用法
使用Pimpl惯用法将实现细节从公有头文件中分离出来。使用Pimpl惯用法时,应采用私有内嵌实现类。只有在.cpp文件中其他类或者自由函数必须访问Impl成员时,才应采用公有内嵌类。
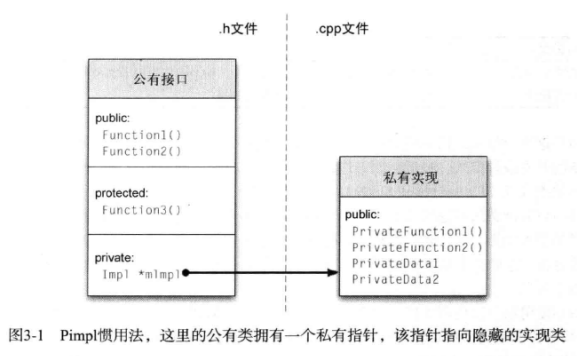
Pimpl惯用法的优缺点:
优点主要包括以下几点:
- 信息隐藏。私有成员现在可以完全隐藏在公有接口之外,使得实现细节得以隐藏。
- 降低耦合。
- 加速编译。将与实现相关的头文件移入.cpp文件带来的另一个隐含结果是API的引用层次得以降低。这将直接影响编译时间。
- 更好的二进制兼容性。采用Pimpl的对象大小从不改变,因为对象总是单个指针的大小。对私有成员变量做任何修改都只会影响在.cpp文件内部的实现类的大小。如果对实现做出重大改变时,对象的二进制表示可以不变。
- 惰性分配。mImpl类可以在需要时再构造,如果类需要分配有限的资源或者高成本资源时,惰性分配很有用,
缺点:
Pimpl惯用法最大的缺点就是必须为你创建的每个对象分配和释放实现对象,这使得对象增接了一个指针,同时因为必须通过指针间接访问所有成员变量,这种额外的调用层次和新增的new和delete开销类似,会引入性能冲击。
详细的设计使用可以参考《C++ API设计》第三章 3.1小节
3. API接口风格
ANSI C API的优点:
- 使用C语言编写API的一个主要原因是,必须与现有的完全用C写的项目集成。虽然越来越多的项目彻底使用C++编写,但是如果客户对API有此约束的话,还是需要用C来编写API。
- 首选C API的另外一个原因是,出于二进制兼容性的考虑。如果你必须维护API库的不同发行版本之间的二进制兼容,那么使用纯C API要比使用C++ API容易得多。
但目前来说,同时支持C和C++的API并不是困难的事。
4. 避免使用友元
在C++中友元是一个类向另外一个类授予其完全访问特权的方法,即友元类或者友元函数可以访问类中受保护的成员和私有成员。
当需要把类分成两个或者多个部分时,且仍需要各部分访问其他部分的私有成员时,就会用到友元。另一种办法是把需要被共享的数据成员和函数暴露出来,把他们从私有转换成公有,从而允许其他类访问。但这意味着向用户暴露实现细节,而细节不应该成为逻辑接口的一部分。
所以接口设计中应该避免使用友元,它往往预示着糟糕的设计,这就等于赋予用户访问API所有的受保护成员和私有成员的权限。
参考
- 《C++ API设计》
- 《C++ Move Semantics》
- 《现代C++语言核心特性解析》
- https://zh.cppreference.com/w/cpp/language/attributes
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2023/10/24/C++-modeling-class-design-guidelines/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)