前言
探究内存一致性的底层原理最好从研究CPU体系结构中内存一致性模型等角度去学习研究,理解内存屏障,笔者在写此篇文章之前先学习了RISC-V的内存屏障相关知识,再来学习C++中的相关处理,虽然笔者对此研究颇浅,也仍有迷惑,但从体系结构的角度去看待问题可能会更有助于理解。
C++ 并发的内存顺序
C++并发编程中,如果不使用锁来保证操作顺序,则通常会使用原子操作。C++中一系列原子操作定义在头文件
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;
std::memory_order 指定内存访问,包括常规的非原子内存访问,如何围绕原子操作排序。在没有任何制约的多处理器系统上,多个线程同时读或写数个变量时,一个线程能观测到变量值更改的顺序不同于另一个线程写它们的顺序。其实,更改的顺序甚至能在多个读取线程间相异。一些类似的效果还能在单处理器系统上出现,因为内存模型允许编译器变换。
库中所有原子操作的默认行为提供序列一致顺序(见后述讨论)。该默认行为可能有损性能,不过可以给予库的原子操作额外的 std::memory_order 参数,以指定附加制约,在原子性外,编译器和处理器还必须强制该操作。
以下对6种内存顺序选项分别进行说明。更为详细的说明和解释可以参考链接。
1.memory_order_relaxed
内存宽松操作,限制最少的自由内存顺序。当原子变量以该选项执行时,仅保证操作本身是原子方式执行。
代码示例:
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<size_t> x{0};
std::atomic<size_t> y{0};
size_t r1, r2;
int main()
{
// 线程 1 :
std::thread t1(
[](){
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
}
);
// 线程 2 :
std::thread t2(
[](){
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
}
);
t1.join();
t2.join();
std::cout << "x - y: " << x << ", " << y << std::endl;
std::cout << "r1 - r2: " << r1 << ", " << r2 << std::endl;
return 0;
}
上述代码多次运行结果不同,理论上可以出现r1 == 42 && r2 == 42等多种情况。
宽松内存顺序的典型的应用是计数器自增,例如 std::shared_ptr 的引用计数器,因为这只要求原子性,但不要求顺序或同步(注意 std::shared_ptr 计数器自减要求与析构函数进行获得释放同步)
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
void f()
{
for (int n = 0; n < 1000; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f);
}
for (auto& t : v) {
t.join();
}
std::cout << "Final counter value is " << cnt << '\n';
}
输出:
Final counter value is 10000
2.memory_order_release和memory_order_acquire
释放和获得顺序选项。释放一般是指原子变量存储,获得是指原子变量的加载,二者一般成对使用。
若线程 A 中的一个原子存储带标签 memory_order_release ,而线程 B 中来自同一变量的原子加载带标签 memory_order_acquire ,则从线程 A 的视角先发生于原子存储的所有内存写入(非原子及宽松原子的),在线程 B 中成为可见副效应,即一旦原子加载完成,则保证线程 B 能观察到线程 A 写入内存的所有内容。
同步仅建立在释放和获得同一原子对象的线程之间。其他线程可能看到与被同步线程的一者或两者相异的内存访问顺序。
代码示例1:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // 绝无问题
assert(data == 42); // 绝无问题
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
示例2, 演示三个线程之间传递性的释放获得顺序
#include <thread>
#include <atomic>
#include <cassert>
#include <vector>
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1()
{
data.push_back(42);
flag.store(1, std::memory_order_release);
}
void thread_2()
{
int expected=1;
while (!flag.compare_exchange_strong(expected, 2, std::memory_order_acq_rel)) {
expected = 1;
}
}
void thread_3()
{
while (flag.load(std::memory_order_acquire) < 2)
;
assert(data.at(0) == 42); // 决不出错
}
int main()
{
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join(); b.join(); c.join();
}
3.memory_order_release和memory_order_consume
释放消费顺序选项。若线程 A 中的原子存储带标签 memory_order_release 而线程 B 中来自同一对象的读取存储值的原子加载带标签 memory_order_consume ,则线程 A 视角中先发生于原子存储的所有内存写入(非原子和宽松原子的),会在线程 B 中该加载操作所携带依赖进入的操作中变成可见副效应,即一旦完成原子加载,则保证线程B中,使用从该加载获得的值的运算符和函数,能见到线程 A 写入内存的内容。
同步仅在释放和消费同一原子对象的线程间建立。其他线程能见到与被同步线程的一者或两者相异的内存访问顺序。
代码示例:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume)))
;
assert(*p2 == "Hello"); // 绝无出错: *p2 从 ptr 携带依赖
assert(data == 42); // 可能也可能不会出错: data 不从 ptr 携带依赖
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
4.memory_order_seq_cst
顺序一致性模型,根据不同的CPU架构可能有不同的处理,可以参考《RISC-V体系结构编程与实践》第15章 第1小节,内存一致性模型中的顺序一致性模型。顺序一致性是所有内存序中性能最差的,对其进行推理和分析要比其他内存次序模型容易的多,因为它会令全部操作形成一个确定的总序列。一般而言,原型设计中的初始化版本都采用memory_order_seq_cst内存次序,当基本操作功能正常后,再逐步放宽其他内存次序,所以从某种意义上讲,采用其他内存次序其实是一项优化。
Sequential consistency模型又称为顺序一致性模型,是控制粒度最严格的内存模型。最早追溯到Leslie Lamport在「1979」年「9」月发表的论文《「How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs」》,在该文里面首次提出了里提出了Sequential consistency定义:
❝ the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program ❞
根据这个定义,在顺序一致性模型下,程序的执行顺序与代码顺序严格一致,也就是说,在顺序一致性模型中,不存在指令乱序。
顺序一致性模型对应的约束符号是memory_order_seq_cst,这个模型对于内存访问顺序的一致性控制是最强的,类似于很容易理解的互斥锁模式,先得到锁的先访问。
假设有两个线程,分别是线程A和线程B,那么这两个线程的执行情况有三种:第一种是线程A先执行,然后再执行线程B;第二种情况是线程 B 先执行,然后再执行线程A;第三种情况是线程A和线程B同时并发执行,即线程A的代码序列和线程B的代码序列交替执行。尽管可能存在第三种代码交替执行的情况,但是单纯从线程A或线程B的角度来看,每个线程的代码执行应该是按照代码顺序执行的,这就顺序一致性模型。总结起来就是:
- 每个线程的执行顺序与代码顺序严格一致
- 线程的执行顺序可能会交替进行,但是从单个线程的角度来看,仍然是顺序执行
为了便于理解上述内容,举例如下:
x = y = 0;
thread1:
x = 1;
r1 = y;
thread2:
y = 1;
r2 = x;
因为多线程执行顺序有可能是交错执行的,所以上述示例执行顺序有可能是:
- x = 1; r1 = y; y = 1; r2 = x
- y = 1; r2 = x; x = 1; r1 = y
- x = 1; y = 1; r1 = y; r2 = x
- x = 1; y = 1;r2 = x; r1 = y
- y = 1; x = 1; r1 = y; r2 = x
- y = 1; x = 1; r2 = x; r1 = y
虽然多线程环境下,线程执行顺序是乱的,但是单纯从线程1的角度来看,执行顺序是x = 1; r1 = y;从线程2角度来看,执行顺序是y = 1; r2 = x。
std::atomic的操作都使用memory_order_seq_cst 作为默认值。如果不确定使用何种内存访问模型,用 memory_order_seq_cst能确保不出错。
顺序一致性的所有操作都按照代码指定的顺序进行,符合开发人员的思维逻辑,但这种严格的排序也限制了现代CPU利用硬件进行并行处理的能力,会严重拖累系统的性能。
在cppreference链接的序列一致顺序小节也有更细致的描述,但其中的描述比较晦涩,代码示例贴出来,再结合上述描述进行理解,相信很快可以看懂下面的例子。代码示例:
#include <thread>
#include <atomic>
#include <cassert>
#include <iostream>
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x()
{
x.store(true, std::memory_order_seq_cst);
}
void write_y()
{
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main()
{
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
std::cout << z << std::endl;
assert(z.load() != 0); // 决不发生
}
测试发现assert 永远为真。
5.与 volatile 的关系
在执行线程中,不能将通过 volatile 泛左值的访问(读和写)重排到同线程内先序于或后序于它的可观测副效应(包含其他 volatile 访问)后,但不保证另一线程观察到此顺序,因为 volatile 访问不建立线程间同步。
另外, volatile 访问不是原子的(共时的读和写是数据竞争),且不排序内存(非 volatile 内存访问可以自由地重排到 volatile 访问前后)。
一个值得注意的例外是 Visual Studio ,其中默认设置下,每个 volatile 写拥有释放语义,而每个 volatile 读拥有获得语义( MSDN ),故而可将 volatile 对象用于线程间同步。标准的 volatile 语义不可应用于多线程编程,尽管它们在应用到 sig_atomic_t 对象时,足以与例如运行于同一线程的 std::signal 处理函数交流。
C++ 无锁编程
无锁编程一定更快吗?
首先需要说明的是,无锁编程并不一定会带来性能上的大幅提升,在实际应用中,临界区一般会较长,临界区越长,加解锁操作的性能损失越微小,无锁编程和有锁编程之间的差距越小。甚至,如果针对特定的任务进行优化,有锁的实现可能性能更佳。
引用链接中知乎上的回答进一步说明:
作者:朱佳顺 链接:https://www.zhihu.com/question/53303879/answer/134936389 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一部分朋友觉得用锁会影响性能,其实锁指令本身很简单,影响性能的是锁争用(Lock Contention),什么叫锁争用,就是你我都想进入临界区,但只能有一个线程能进去,这样就影响了并发度。可以去看看glibc中pthread_mutex_lock的源码实现,在没有contention的时候,就是一条CAS指令,内核都没有陷入;在contention发生的时候,就选择陷入内核然后睡觉,等待某个线程unlock后唤醒(详见Futex)。
“只有一个线程在临界区”这件事对lockfree也是成立的,只不过所有线程都可以进临界区,最后只有一个线程可以make progress,其它线程再做一遍。
所以contention在有锁和无锁编程中都是存在的,那为什么无锁有些时候会比有锁更快?他们的不同体现在拿不到锁的态度:有锁的情况就是睡觉,无锁的情况就不断spin。睡觉这个动作会陷入内核,发生context switch,这个是有开销的,但是这个开销能有多大呢,当你的临界区很小的时候,这个开销的比重就非常大。这也是为什么临界区很小的时候,换成lockfree性能通常会提高很多的原因。
再来看lockfree的spin,一般都遵循一个固定的格式:先把一个不变的值X存到某个局部变量A里,然后做一些计算,计算/生成一个新的对象,然后做一个CAS操作,判断A和X还是不是相等的,如果是,那么这次CAS就算成功了,否则再来一遍。如果上面这个loop里面“计算/生成一个新的对象”非常耗时并且contention很严重,那么lockfree性能有时会比mutex差。另外lockfree不断地spin引起的CPU同步cacheline的开销也比mutex版本的大。
lockfree的意义不在于绝对的高性能,它比mutex的优点是使用lockfree可以避免死锁/活锁,优先级翻转等问题。但是因为ABA problem、memory order等问题,使得lockfree比mutex难实现得多。
除非性能瓶颈已经确定,否则还是乖乖用mutex+condvar,等到以后出bug了就知道mutex的好了。如果一定要换lockfree,请一定要先profile,profile,profile!请确保时间花在刀刃上。
无锁编程的基础
无锁编程的优点主要是避免了死锁的发生,但同时它也有两个缺点:
- 第一个缺点是优点的反面。CAS尝试失败的线程会保持忙碌,这解决了优先级的问题,但是代价非常高:在高并发的环境下,大量CPU时间浪费在忙等上,这只是为了重复计算。更糟糕的是,这些线程为了争夺对单个原子变量的访问权,会从其他无关计算的线程中夺走CPU资源。
- 第二个缺点是大多数并发程序不容易编写和理解,并且无锁程序会更难设计和实现。
原子操作是无锁编程的基石,原子操作是不可分隔的操作,一般通过CAS(Compare and Swap)操作实现,CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。
C++11之后提供了原子类型atomic,同时提供了一系列原子操作,使用原子类型定义共享变量,可以减少修改时对原子变量的加锁解锁,节省系统开销,也会避免线程因阻塞而频繁的切换。
以下基础概念内容转载自链接
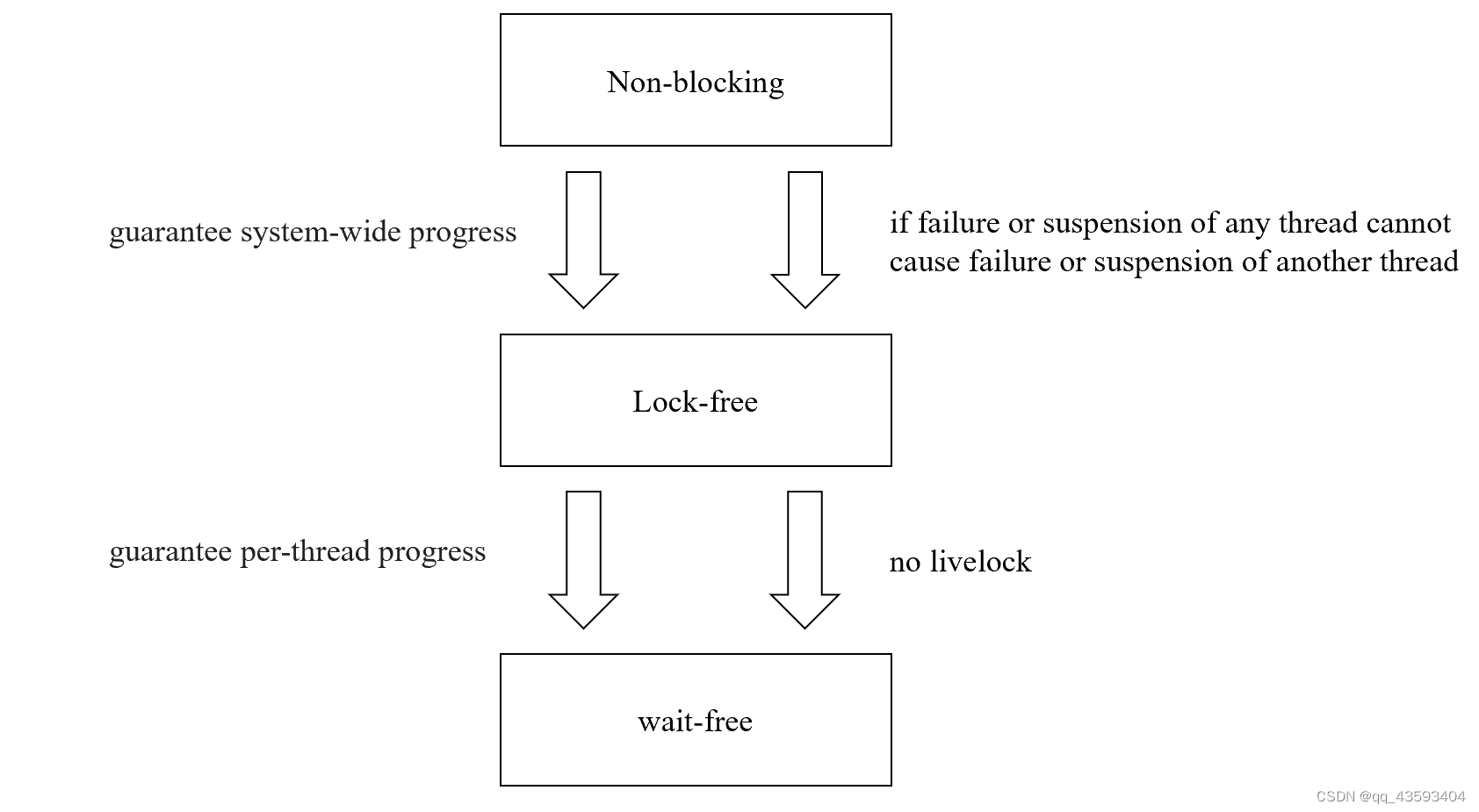
首先阐述几个概念, 无锁化(lock free),无等待(wait free),非阻塞(non-blocking)。
阻塞与非阻塞
从OS的角度出发,把这里的阻塞认为是操作系统中阻塞、线程调度的概念。
这时阻塞是一个系统调用,当线程调用该阻塞调用时,当线程阻塞时进行睡眠状态,操作系统可以从调度器中删除该线程,此时该线程不会占用CPU的时间片,而另一个事件发生时,线程再被放回调度器,并分配时间片运行,此时正在运行阻塞调用的线程称为阻塞线程那么此时非阻塞函数就是那些不阻塞的函数。
非阻塞数据结构是指所有操作都是非阻塞的数据结构。所有无锁数据结构本质上都是非阻塞的。此时我们知道自旋锁(spinlock)是非阻塞同步的一个例子:如果一个线程有锁,那么等待的线程不会挂起,而是必须循环,直到持有锁的线程释放它。自旋锁这种忙碌等待循环的算法并不是lock free的。(因为如果持有锁的线程挂起,那么没有线程可以继续运行。)
lock free
这里lock free和non-blocking主要区别就是如果在该lock free数据结构上执行操作的任何线程在该操作期间的任何时刻被挂起,那么访问该数据结构的其他线程必须仍然能够完成它们的任务。而lock-free的数据结构概念上是不使用任何互斥锁的数据结构。所谓的无锁有很多种无锁,即实现方式多种多样。
举个例子,一个多线程访问的读写共享队列既可以通过CAS(Compare And Swap),也可以通过分区实现数据并行,将共享队列拆分到多个线程,每个线程负责一个队列。 (注:前者方案会出现数据争抢、ABA问题,后者方案则会出现负载均衡问题,由此出现work stealing的解决方案,该方案又会引出针对每个线程的队列加锁问题,这里问题的具体讨论我会放到线程池的方案总结与实现篇,这里先带过)。
同时无锁化的数据结构有可能是限制于某些场景的,也就是by case的。以生产者消费者队列为例,存在SPSC(single-producer/single-consumer)以及MPMC(multi-producers/multi-consumers)等。前者的无锁化不需要使用CAS,通过ringbuffer使用write index和read index两个index的原子变量来实现,而后者则需要可能需要CAS等硬件原语来实现,效率会差很多,此时前者ringbuffer的方案是不能用于后者SPSC的情况的。(注:ringbuffer两个index原子变量的方案也可以适用于一部分SPMC(single-producer/multi-consumers)的情况,但存在一些限制条件)
最后,数据结构是无锁的,并不意味着线程不需要相互等待。在无锁算法中,当存在高争用时,线程可能会发现它必须重试其操作的次数不受限制。也就是可能会出现活锁(livelock)的情况,这也是lock-free和wait-free的主要区别。
wait-free
wait-free数据结构是一种lock-free的数据结构,它具有一个附加属性,即不管其他线程的行为如何,访问该数据结构的每个线程都可以在有限的步骤内完成其操作。而由于与其他线程的冲突,可能涉及无限次重试的算法因此不是无等待的。换句话说,也就是没有活锁(livelock)这种情况。
ABA问题
下文实现的无锁栈和无锁队列都存在ABA问题,ABA问题的具体解释和解决方案可以参考wiki:https://en.wikipedia.org/wiki/ABA_problem。以下结合wiki中的例子简单说明一下。
代码实例:
/* Naive lock-free stack which suffers from ABA problem.*/
class Stack {
std::atomic<Obj*> top_ptr;
//
// Pops the top object and returns a pointer to it.
//
Obj* Pop() {
while (1) {
Obj* ret_ptr = top_ptr;
if (!ret_ptr) return nullptr;
// For simplicity, suppose that we can ensure that this dereference is safe
// (i.e., that no other thread has popped the stack in the meantime).
Obj* next_ptr = ret_ptr->next;
// If the top node is still ret, then assume no one has changed the stack.
// (That statement is not always true because of the ABA problem)
// Atomically replace top with next.
if (top_ptr.compare_exchange_weak(ret_ptr, next_ptr)) {
return ret_ptr;
}
// The stack has changed, start over.
}
}
//
// Pushes the object specified by obj_ptr to stack.
//
void Push(Obj* obj_ptr) {
while (1) {
Obj* next_ptr = top_ptr;
obj_ptr->next = next_ptr;
// If the top node is still next, then assume no one has changed the stack.
// (That statement is not always true because of the ABA problem)
// Atomically replace top with obj.
if (top_ptr.compare_exchange_weak(next_ptr, obj_ptr)) {
return;
}
// The stack has changed, start over.
}
}
};
上述代码可以正常阻止并发访问的问题,但是还是会有ABA问题。考虑以下过程:
Stack initially contains top → A → B → C
Thread 1 starts running pop:
ret = A;
next = B;
此时 线程1相当于执行到Pop()函数compare_exchange_weak之前,此时进行线程切换,执行线程2。
{ // Thread 2 runs pop:
ret = A;
next = B;
compare_exchange_weak(A, B) // Success, top = B
return A;
} // Now the stack is top → B → C
{ // Thread 2 runs pop again:
ret = B;
next = C;
compare_exchange_weak(B, C) // Success, top = C
return B;
} // Now the stack is top → C
delete B;
{ // Thread 2 now pushes A back onto the stack:
A->next = C;
compare_exchange_weak(C, A) // Success, top = A
}
线程2执行完上述流程,栈中元素为 top → A → C
此时线程1恢复运行,执行compare_exchange_weak:
compare_exchange_weak(A, B)
这条指令会执行成功,因为此时top == ret,此时将会设置top为next,也就是B。但是在线程2执行过程中已经删除了B,访问已经释放的内存将会报错,产生未定义的行为。可以看出,这类ABA的bug非常难以定位。
无锁栈实现
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
#include <iostream>
template<typename T>
struct Node
{
Node(){}
Node(const T &value) : data(value), next(nullptr) { }
T data;
Node *next = nullptr;
};
/*头插和头pop的方法
*/
template<typename T>
class LockFreeStack
{
std::atomic<Node<T> *> head{nullptr};
std::atomic<int> size{0};
public:
void PushFront(const T &value)
{
auto *node = new Node<T>(value);
node->next = head.load();
while(!head.compare_exchange_weak(node->next, node)); //②
size.fetch_add(1);
}
bool PopFront(T &value)
{
Node<T>* temp = head.load();//留一个快照snapshot
do {
if (temp == nullptr) return false;//这句判断要在循环里面
} while (!head.compare_exchange_weak(temp,temp->next));
value = temp->data;//? before or after and tail behind this is a question
delete temp;
size.fetch_sub(1);
return true;
}
int32_t Size() { return size.load(); }
};
首先解释一下CAS硬件原语,这条复杂的指令由硬件实现为原子性的,即A.CAS(B,C),如果当前值A和期望值B相等时,把预测值C赋值给当前值A,如果当前值A与期望值不等时,把当前值A赋值给期望值B
简单解释一下算法流程:
node->next = head.load();对于每个线程来说,将新node与head相连,此时做CAS检查,head是否等于node->next,如果相等,head是该线程读取的head,node连接到head之前,而后将让head指针指向node节点,而如果head与node->next不相等,则说明此时的head已经被其他线程更新,则连接应该针对该新head重新连接,于是再次执行node->next = head.load()。
无锁栈和有锁栈的性能对比
简单对push操作做一下性能对比:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
#include <iostream>
#include <chrono>
#include <mutex>
using namespace std;
template<typename T>
struct Node
{
Node(){}
Node(const T &value) : data(value), next(nullptr) { }
T data;
Node *next = nullptr;
};
/*头插和头pop的方法
*/
template<typename T>
class LockFreeStack
{
std::atomic<Node<T> *> head{nullptr};
std::atomic<int> size{0};
public:
void PushFront(const T &value)
{
auto *node = new Node<T>(value);
node->next = head.load();
while(!head.compare_exchange_weak(node->next, node)); //②
size.fetch_add(1);
}
bool PopFront(T &value)
{
Node<T>* temp = head.load();//留一个快照snapshot
do {
if (temp == nullptr) return false;//这句判断要在循环里面
} while (!head.compare_exchange_weak(temp, temp->next));
value = temp->data;//? before or after and tail behind this is a question
delete temp;
size.fetch_sub(1);
return true;
}
int32_t Size() { return size.load(); }
};
template<typename T>
class WithLockStack
{
std::mutex mtx;
Node<T>* head{nullptr};
int size{0};
public:
void PushFront(const T &value)
{
auto *node = new Node<T>(value);
{
std::lock_guard<std::mutex> lock(mtx);
node->next = head;
head = node;
size++;
}
}
bool PopFront(T &value){
Node<T>* temp = head;
{
std::lock_guard<std::mutex> lock(mtx);
if(head== nullptr) return false;
head = head->next;
value = temp->data;
free(temp);
size--;
}
return true;
}
};
int main()
{
const int SIZE = 1000000;
//有锁测试
auto start = chrono::steady_clock::now();
WithLockStack<int> wl_stack;
for(int i = 0; i < SIZE; ++i)
{
wl_stack.PushFront(i);
}
auto end = chrono::steady_clock::now();
chrono::duration<double, std::micro> micro = end - start;
cout << "with lock stack costs micro:" << micro.count() << endl;
//无锁测试
atomic<int> x{0};
start = chrono::steady_clock::now();
LockFreeStack<int> lf_stack;
for(int i = 0; i < SIZE; ++i)
{
lf_stack.PushFront(i);
}
end = chrono::steady_clock::now();
micro = end - start;
cout << "free lock stack costs micro:" << micro.count() << endl;
return 0;
}
输出:
with lock stack costs micro:110049
free lock stack costs micro:92738.2
无锁队列
无锁队列的实现和性能对比涉及到的细节和数据结构比较多,需要单独开一篇文章细说。
参考
- https://zh.cppreference.com/w/cpp/atomic/memory_order
- https://mp.weixin.qq.com/s/HdP5NcQIdzfznGwcHLTvMw
- https://zhuanlan.zhihu.com/p/649203972
- https://zhuanlan.zhihu.com/p/454915077
- https://www.zhihu.com/question/536176990
- https://www.zhihu.com/question/53303879/answer/134936389
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2023/08/10/C++-lock-free-programming-and-atomic-memory-consistency/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)