背景介绍
随着工程项目的迭代深入,对程序的性能、内存占用等需求会越来越高,因此性能调优是程序走向稳定成熟的必经之路。C++程序的性能调优可以借助很多工具,工具的安装、环境依赖以及使用不尽相同,本文意在记录常用的C++性能调优工具和可视化工具的使用方式,便于日常迅速查询,进行性能分析和调优。
1.gperftools(originally Google Performance Tools)
在golang程序性能调优中,常用到pprof工具作为性能分析和可视化的工具,可以用来cpu profile,memory profile等。同样的,在C++中也可以使用这个工具,
这个工具就是gperftools,具体的使用可以参考GitHub首页的readme,这里列举C++中常用的工具流程。
安装
安装libunwind
64位操作系统需要安装libunwind,gperftools推荐版本是libunwind-0.99-beta,详见gperftools/INSTALL里的说明。
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99-beta.tar.gz
tar -zxvf libunwind-0.99-beta.tar.gz
cd libunwind-0.99-beta/
./configure
make
make install
因为默认的libunwind安装在/usr/local/lib目录下,需要将这个目录添加到系统动态库缓存中。
echo "/usr/local/lib" > /etc/ld.so.conf.d/usr_local_lib.conf
/sbin/ldconfig
安装graphviz
Graphviz是一个由AT&T实验室启动的开源工具包,用于绘制DOT语言脚本描述的图形,gperftools依靠此工具生成图形分析结果。 安装命令:apt install graphviz
生成图像时依赖ps2pdf
安装命令: apt install ghostscript
安装perftools
git clone https://github.com/gperftools/gperftools.git
cd gperftools/
./autogen.sh
./configure
make
make install
如果遇到相关问题报错可以参考:
遇到的问题1:
[root@10-8-152-53 gperftools]# ./autogen.sh
configure.ac:174: error: possibly undefined macro: AC_PROG_LIBTOOL
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
autoreconf: /usr/bin/autoconf failed with exit status:
解决方法:apt install libtool
遇到的问题2:
[root@hb06-ufile-132-199 gperftools]# ./autogen.sh
libtoolize: putting macros in AC_CONFIG_MACRO_DIR, `m4'.
libtoolize: copying file `m4/libtool.m4'
libtoolize: copying file `m4/ltoptions.m4'
libtoolize: copying file `m4/ltsugar.m4'
libtoolize: copying file `m4/ltversion.m4'
libtoolize: copying file `m4/lt~obsolete.m4'
configure.ac:159: installing './compile'
configure.ac:22: installing './config.guess'
configure.ac:22: installing './config.sub'
configure.ac:23: installing './install-sh'
configure.ac:174: error: required file './ltmain.sh' not found
configure.ac:23: installing './missing'
解决方法:aclocal && autoheader && autoconf && automake –add-missing 参考了https://stackoverflow.com/questions/22603163/automake-error-ltmain-sh-not-found
链接
需要连接的库:profiler tcmalloc unwind
使用举例
Cpu Profiler
头文件: #include <gperftools/profiler.h>
修改启动方式运行
该方法不需要侵入到源码,在编译链接之后,需要使用一下命令启动程序:
CPUPROFILE=./test.prof ./a.out
运行后会生成test.prof的性能统计数据文件,然后使用pprof可以生成text或者graph的分析报告,text不够直观,需要自己去查找相应的调用路径,这里推荐使用生成graph的方式:
- 生成pdf
pprof --pdf a.out test.prof > test.pdf
- 生成图片
生成图片需要依赖graphviz, 先生成.dot格式文件:
pprof --dot ./a.out test.prof > test.dot
然后转换成图片格式:
dot -Tpng test.dot -o test.png
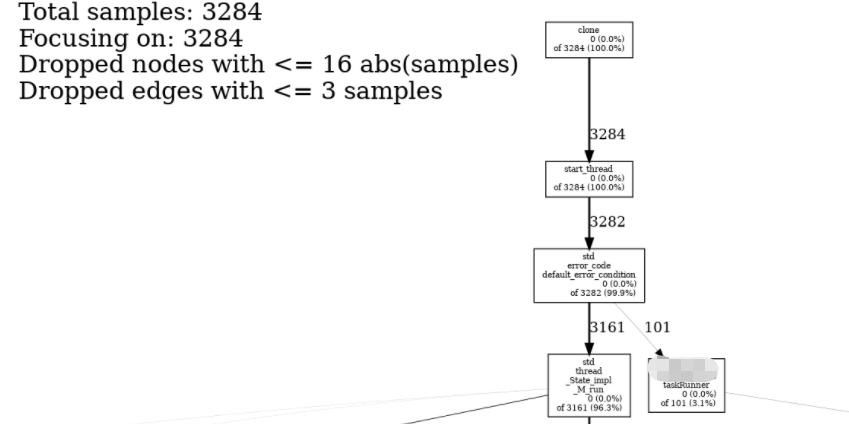
图中节点的含义可以参考GitHub上的解释。
不修改启动方式,但需要侵入代码的方式运行
可以直接在代码中插入性能分析函数,示例如下:
#include <gperftools/profiler.h>
#include <iostream>
using namespace std;
void func1() {
int i = 0;
while (i < 100000) {
++i;
}
}
void func2() {
int i = 0;
while (i < 200000) {
++i;
}
}
void func3() {
for (int i = 0; i < 1000; ++i) {
func1();
func2();
}
}
int main(){
ProfilerStart("test.prof"); // 指定所生成的profile文件名
func3();
ProfilerStop(); // 结束profiling
return 0;
}
需要连接profiler,tcmalloc, unwind三个库,然后运行程序后会产生test.prof文件,生成text或者图片的方式同上。
Heap Profiler
内存分析同样有侵入式和非侵入式两种方式启动程序,头文件: #include <gperftools/heap-profiler.h>。
修改启动方式运行
HEAPPROFILE=test ./a.out //注意这里HEAPPROFILE=test指定的是生成文件的前缀名
不修改启动方式运行,修改代码的方式
#include "gperftools/heap-profiler.h"
#include <iostream>
using namespace std;
void func1() {
int i = 0;
while (i < 100000) {
++i;
}
}
void func2() {
int i = 0;
while (i < 200000) {
++i;
}
}
void func3() {
for (int i = 0; i < 1000; ++i) {
func1();
func2();
}
}
int main(){
HeapProfilerStart("test"); // 指定所生成的profile文件名的前缀
func3();
HeapProfilerStop(); // 结束profiling
return 0;
}
采用上述方式启动程序后,Heap Profiler会定期进行内存采样并生成统计数据,相关打印如下:
Starting tracking the heap
Dumping heap profile to test_0524.0001.heap (1024 MB allocated cumulatively, 53 MB currently in use)
同样的我们使用命令:
pprof --dot ./a.out test_0524.0001.heap > test_0524.0001.dot
dot -Tpng test_0524.0001.dot -o test_0524.0001.png
即可生成调用关系和分析数据的图片:
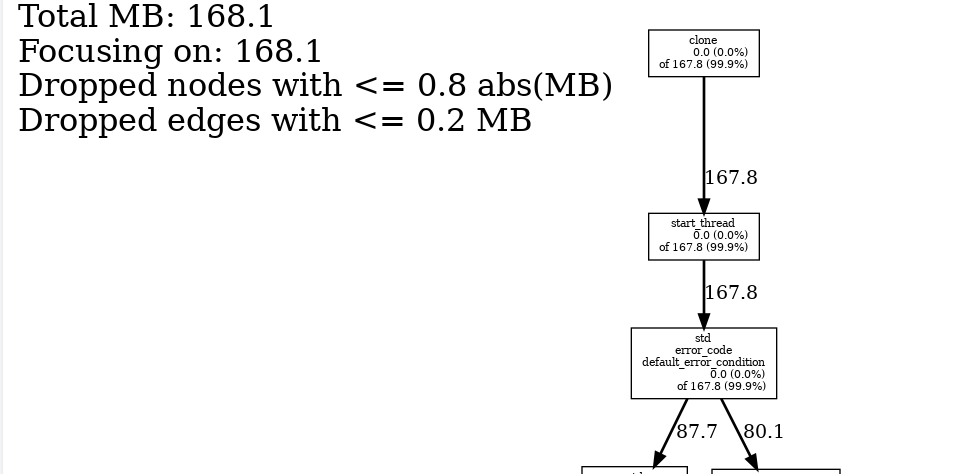
更多配置项
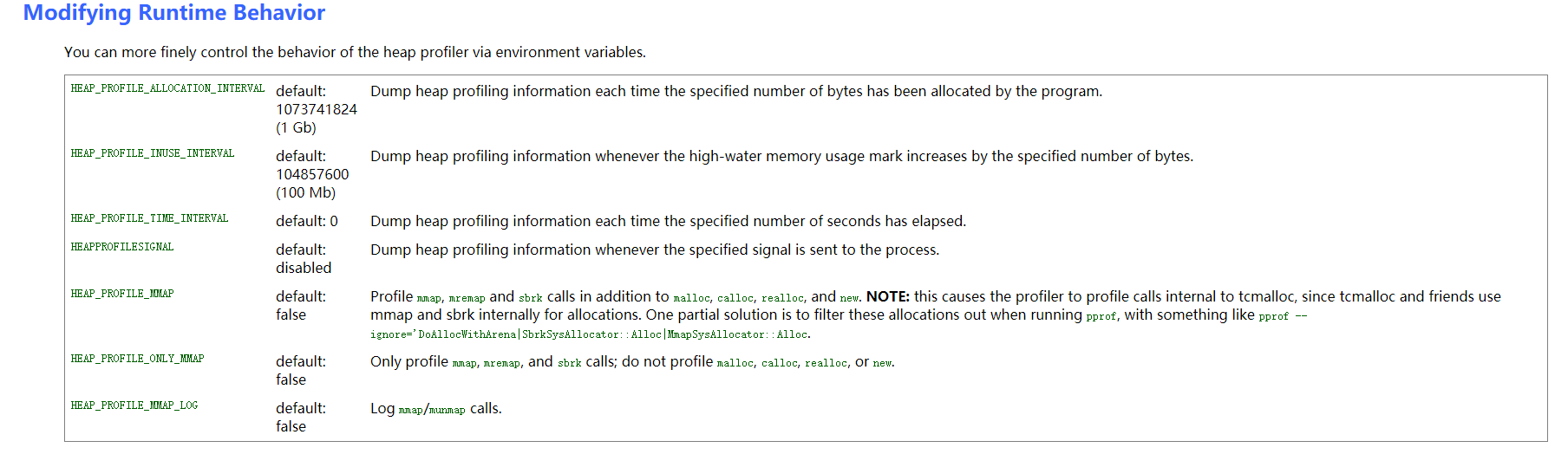
更多环境变量设置和配置选项参考gperftools wiki : https://gperftools.github.io/gperftools/heapprofile.html
wiki –> Documentation有详细配置项的使用说明,例如在生成图时排除某些函数等。
关于gperftools更多功能和使用方式请参考 https://github.com/gperftools/gperftools。
2.Valgrind Massif内存堆栈分析工具及其可视化工具
之前一直使用valgrind定位C++程序内存泄漏和越界问题,最近项目需要分析软件系统内存占用情况,了解到valgrind可以对内存堆栈的申请占用进行采样分析,在ubuntu的桌面版下还可以使用可视化工具直观的查看内存消耗和调用栈。
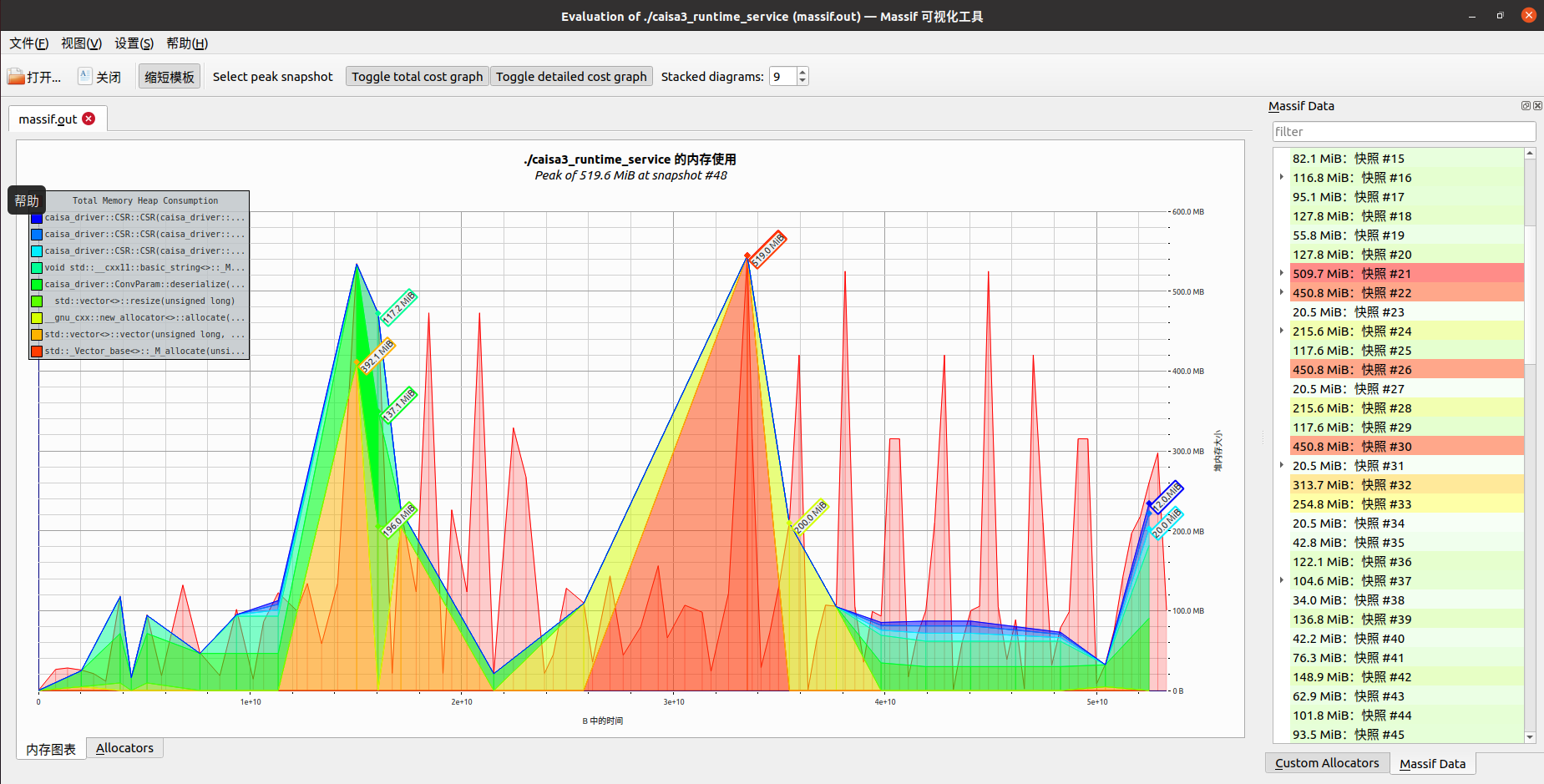
需要先说明的是,valgrind是通过定期采样内存数据生成内存数据文件的,所以数据展示的是某个时刻程序中内存占用情况。先来看一张效果图:
Valgrind工具的安装等不在此说明。
Massif命令行选项
Massif工具的官网介绍可以参考:http://valgrind.org/docs/manual/ms-manual.html
这里对常用的选项进行说明:
user options for Massif:
--heap=no|yes profile heap blocks [yes]
--heap-admin=<size> average admin bytes per heap block;
ignored if --heap=no [8]
--stacks=no|yes profile stack(s) [no]
--pages-as-heap=no|yes profile memory at the page level [no]
--depth=<number> depth of contexts [30]
--alloc-fn=<name> specify <name> as an alloc function [empty]
--ignore-fn=<name> ignore heap allocations within <name> [empty]
--threshold=<m.n> significance threshold, as a percentage [1.0]
--peak-inaccuracy=<m.n> maximum peak inaccuracy, as a percentage [1.0]
--time-unit=i|ms|B time unit: instructions executed, milliseconds
or heap bytes alloc'd/dealloc'd [i]
--detailed-freq=<N> every Nth snapshot should be detailed [10]
--max-snapshots=<N> maximum number of snapshots recorded [100]
--massif-out-file=<file> output file name [massif.out.%p]
数据采集
valgrind -v --tool=massif --time-unit=B --detailed-freq=1 --massif-out-file=./massif.out ./test_corofile
运行一段时间后 可以使用kill + pid的方式停止程序,不要使用 kill -9 + pid的方式,可能会导致采样失败。
运行结束后会在当前文件夹生成massif.out文件。程序运行的环境可能为无界面的服务器,这个数据分析文件也可以在不同的机器环境中进行分析,可以使用虚拟机安装ubuntu桌面版,在进行可视化分析。
ms_print 分析采样文件
文本输出可以使用ms_print命令:
ms_print ./massif.out
massif-visualizer 可视化分析采样文件
使用ms_print文本输出不够直观,可以在ubuntu桌面版安装massif-visualizer:
sudo apt install massif-visualizer
双击 massif-visualizer 启动软件之后,打开并选中某个 massif.out 文件,或者用命令行的方式打开:
massif-visualizer ./massif.out
界面上可以清晰直观的看到内存使用变化、调用栈等数据,点击界面下面的 Allocators 按钮之后,可以看到内存分配的排行榜。
CPU性能分析
1.上下文切换
此章节参考文章《Linux操作系统通过实战理解CPU上下文切换》结合自己的环境做实验进行总结。
CPU上下文其实是支撑任务运行的环境,而这些环境的硬件条件便是CPU寄存器和程序计数器。CPU寄存器是CPU内置的容量非常小但是速度极快的存储设备,程序计数器则是CPU在运行任何任务时必要的,里面记录了当前运行任务的行数等信息,这就是CPU上下文。
根据任务的不同,CPU上下文切换可以分为进程上下文切换、线程上下文切换和中断上下文切换。
进程上下文切换
在Linux中,Linux按照特权等级,将进程的运行空间分为内核空间和用户空间:
- 内核空间具有最高权限,可以直接访问所有资源
- 用户空间只能访问受限资源,不能直接访问内存等硬件设备,要想访问这些特权资源,必须通过系统调用
对于一个进程来说,一般是运行在用户态的,但是当需要访问内存、磁盘等硬件设备的时候需要陷入到内核态中,也就是要从用户态到内核态的转变,而这种转变需要通过系统调用来实现,例如一个打开文件的操作,需要调用open()打开文件,read()读取文件内容,write()将文件内容输出到控制台,最后close()关闭文件,这就是系统调用
在系统调用的过程中同样发发生了CPU上下文切换:
- CPU寄存器里面原来用户态的指令位置,需要先保存起来,接着运行内核态代码
- CPU寄存器需要更新为内核态指令的位置,执行内核态代码
系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后切换为用户空间,所以一次系统调用的过程,会发生两次的CPU上下文切换但是我们一般说系统调用是特权模式切换而不是上下文切换,因为这里没有涉及到虚拟内存等这些进程用户态的资源,也不会切换进程是属于进程之内的上下文切换,进程是由内核来管理和调度的,进程的切换只能发生在内核态,所以进程的上下文包含了虚拟内存、栈、全局变量等用户空间的资源,还包含了内核堆栈、寄存器等内核空间的状态,所以进程的上下文切换要比系统调用更多一步,保存该进程的虚拟内存、栈等用户空间的资源,进程上下文切换一般需要几十纳秒到数微秒的CPU时间,当进程上下文切换次数比较多的情况下爱,将导致CPU将大量的时间耗费在寄存器、内核栈即虚拟内存等资源的保存和恢复上,另外,Linux通过TLB快表来管理虚拟内存到物理内存的映射关系,当虚拟内存更新之后,需要刷新缓存,在这多处理系统上是很复杂的,因为多个处理器共享一个缓存。
下面再来说说什么时候会进行进程的上下文切换,其实就是进程在被调度的时候需要切换上下文,可能是主动地,也有可能是被动的
- 系统进程正常调度算法导致进程上下文切换,例如目前使用的时间片轮转算法,当一个进程的时间片耗尽之后,CPU会进项进程的调度切换到其他进程
- 进程在资源不足的时候,会被挂起例如在等待IO或者内存不足的时候,会主动挂起,并且等待系统调度其他进程
- 当进程通过一些睡眠函数sleep()主动挂起的时候,也会重新调度
- 当有高优先级的进程运行时,当前进程也会被挂起
- 当发生硬件中断时,CPU上的进程会被中断挂起
线程上下文切换
线程是调度的基本单位,而进程则是资源拥有的基本单位,也就是说对于内核中的任务调度是以线程为单位,但是进程只是给线程提供了虚拟内存、全局变量等资源,进程与线程之间的区别这里不再介绍 那么线程上下文的切换,其实分为两种情况:
- 前后两个线程属于不同进程,因为资源不共享,所以这时候的线程上下文切换和进程上下文切换是一致的
- 前后两个线程属于同一个进程,因为虚拟内存是共享的,所以在切换的时候,虚拟内存这些资源保持不动,只有切换线程的私有数据、寄存器等不共享的资源
所以同进程内的线程切换要比多进程内的线程切换消耗更少的资源
中断上下文切换
中断是为了快速响应硬件的事件,简单来shu就是计算机停下当前的事情,去处理其他的事情,然后在回来继续执行之前的任务,例如我们在调用print函数的时候,其实汇编的底层会帮我们调用一条 int 0x80的指令,便是调用0x80号中断。 当然,中断要先将当前进程的状态保存下来,这样中断结束后进程仍然可以从原来的状态恢复运行,中断上下文的切换并不涉及进程的用户态,所以当中断程序打断了正在处于用户态的进程,不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源,只需要保存和恢复这个进程的内核态中的资源包括CPU寄存器、内核堆栈等。 对于同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生,一般来说中断程序都执行比较快短小精悍,以便快速结束执行之前的任务。当中断上下文切换次数比较多的时候,会耗费大量的CPU。
怎么查看系统上下文
上面已经介绍到CPU上下文切换分为进程上下文切换、线程上下文切换、中断上下文切换,那么过多的上下文切换会把CPU的时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为系统性能大幅下降的一个因素 所以我们可以使用vmstat这个工具来查询系统的上下文切换情况,vmstat是一个常用的系统性能分析工具,可以用来分析CPU上下文切换和中断的次数。

需要特别关注的是:
- cs(context switch):每秒上下文切换的次数
- in(interrupt):每秒中断的次数
- r(Running or Runnable):就绪队列的长度,也就是正在运行和等待CPU的进程
- b(Blocked):处于不可中断睡眠状态的进程数
vmstat是给出整个系统总体的上下文切换情况,要想查看每个进程的详细情况就需要使用pidstat,加上-w选项就可以查看进程上下文切换的情况。
pidstat具体参数项的信息可以通过 man pidstat查看。
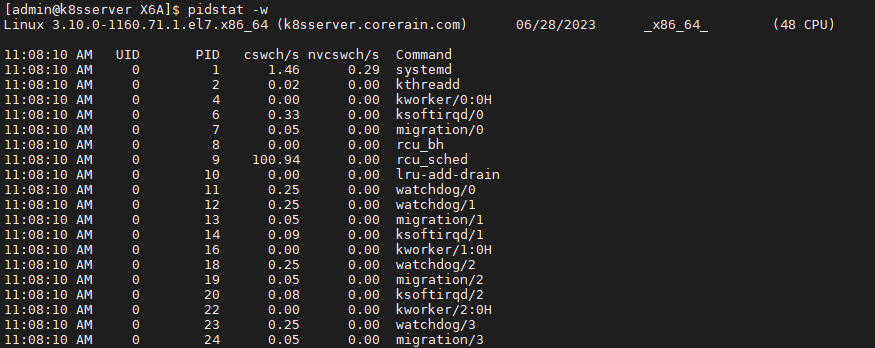
需要特别关注的是:
- cswch(voluntary context switches):表示每秒自愿上下文切换的次数
- nvcswch(non voluntary context switches):表示每秒非自愿上下文切换的次数
这两个概念的分别含义:
- 自愿上下文切换:进程无法获取所需的资源,导致的上下文切换,例如IO、内存等资源不足时,就会发生自愿上下文切换
- 非自愿上下文切换:进程由于时间片已到等时间,被系统强制调度,进而发生的上下文切换,例如大量的进程都在争抢CPU时,就容易发生非自愿上下文切换
实战分析
通过上面的工具已经可以初步查看到系统上下文切换的次数,但是当系统上下文切换的次数为多少时是不正常的呢? 案例使用sysbench工具来模拟多线程调度切换的情况,sysbench是一个多线程的基准测试工具,可以模拟上下文切换过多的问题。
运行环境是4个CPU,共4物理核的虚拟机环境。
首先在第一个终端运行stsbench,模拟多线程切换问题。以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题 。
sysbench --threads=10 --max-time=300 threads run
然后在第二个终端运行vmstat,每1秒查看上下文切换的情况。
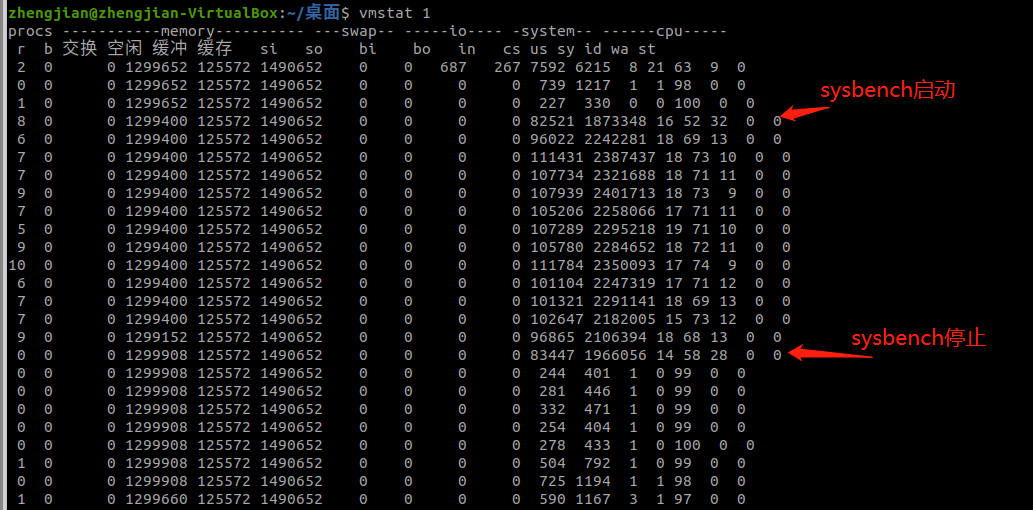
有sysbench启动到停止,可以观察到如下指标变化:
- r列:就绪队列的长度已经到了8左右,已经超过了4个cpu,所以会有大量的CPU竞争
- us(user)列和sy(system)列,这两列的CPU使用率偏高,并且大量是由sy造成的,说明CPU主要是被内核占用了
- in(interrupt):in列的数值也到了几万的级别,所以中断处理也是一个问题
接着使用pidstat来查看是那一个进程出现了问题,由于pidstat默认是显示进程的指标数据,但是我们使用sysbench模拟的线程的数据,所以需要加上-t选项:
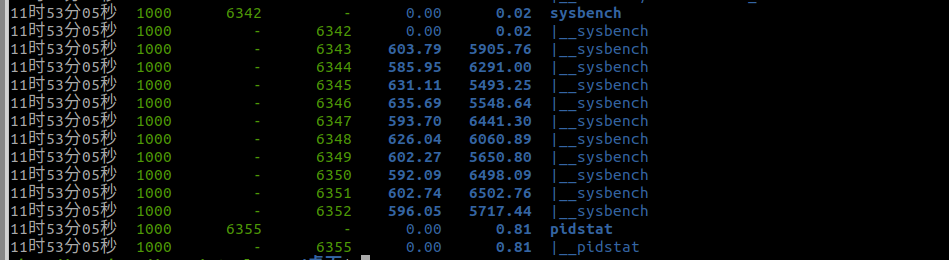
所以到这里可以分析出是sysbench的子线程的上下文切换次数有很多。 还有一个问题,在使用vmstat的时候,发现in指标的数据也比较多,那么我们需要找出是什么类型的中断导致了中断上升,中断肯定是发生在内核态,但是pidstat只是一个进程的性能分析工具,并不提供任何关于中断的详细信息。
我们可以从/proc/interrupts这个只读文件中读取,/proc是一个虚拟文件系统,用于内核空间和用户空间之间的通信,/proc/interrupts则提供了一个只读的中断使用情况,可以使用cat命令查看/proc/interrupts可以发现变化速度最快的是重调度中断RES,这个中断类型表示唤醒空闲状态的CPU来调度新的任务运行,也被成为处理器中断。使用watch -n 1 'cat /proc/interrupts'命令观察各个数值变化频率:
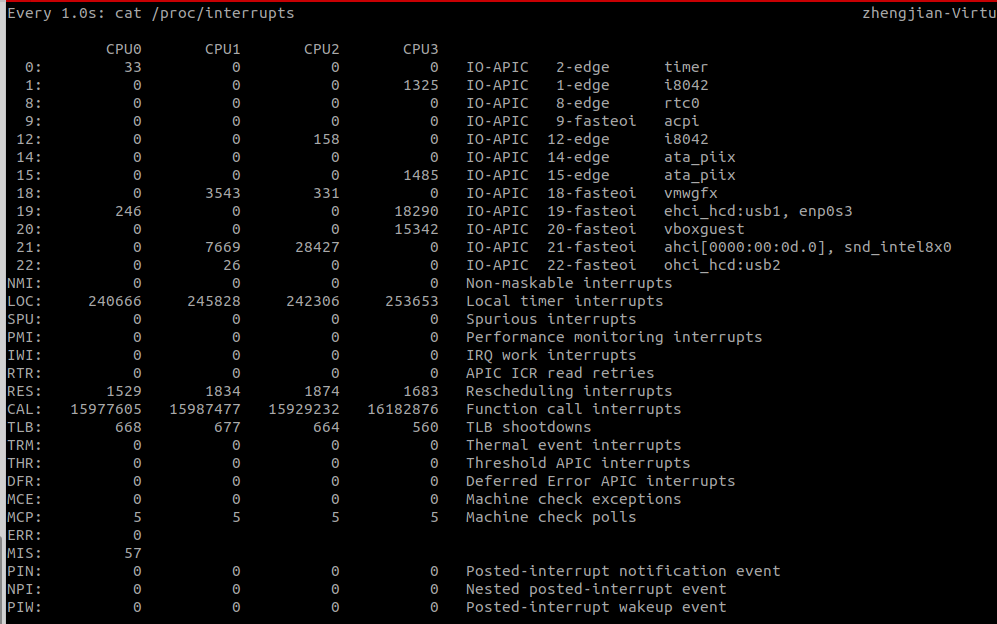
这个数值其实取决于系统本身的 CPU 性能,在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题,这个时候还要根据上下文切换的类型,做具体的分析,例如:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU的确成了瓶颈;
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件。
内存性能分析
1.Swap占用分析
当发生了内存泄漏时,或者运行了大内存的应用程序,导致系统的内存资源紧张时,系统又会如何应对呢?
我们先来看后一个可能结果,内存资源紧张导致的 OOM(Out Of Memory),相对容易理解,指的是系统杀死占用大量内存的进程,释放这些内存,再分配给其他更需要的进程。
接下来再看第一个可能的结果,内存回收,也就是系统释放掉可以回收的内存,比如我前面讲过的缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做文件页(File-backed Page)。
大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。这些脏页,一般可以通过两种方式写入磁盘。可以在应用程序中,通过系统调用 fsync ,把脏页同步到磁盘中;也可以交给系统,由内核线程 pdflush 负责这些脏页的刷新。
除了缓存和缓冲区,通过内存映射获取的文件映射页,也是一种常见的文件页。它也可以被释放掉,下次再访问的时候,从文件重新读取。
除了文件页外,还有没有其他的内存可以回收呢?比如,应用程序动态分配的堆内存,也就是我们在内存管理中说到的匿名页(Anonymous Page),是不是也可以回收呢?
我想,你肯定会说,它们很可能还要再次被访问啊,当然不能直接回收了。非常正确,这些内存自然不能直接释放。但是,如果这些内存在分配后很少被访问,似乎也是一种资源浪费。是不是可以把它们暂时先存在磁盘里,释放内存给其他更需要的进程?其实,这正是 Linux 的 Swap 机制。Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
Swap原理
前面提到,Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程。
所谓换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
而换入,则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
所以你看,Swap 其实是把系统的可用内存变大了。这样,即使服务器的内存不足,也可以运行大内存的应用程序。
既然 Swap 是为了回收内存,那么 Linux 到底在什么时候需要回收内存呢?前面一直在说内存资源紧张,又该怎么来衡量内存是不是紧张呢?
一个最容易想到的场景就是,有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是 kswapd0。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。
kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
我们可以看到,一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。
实际上,前面提到的三个内存阈值(页最小阈值、页低阈值和页高阈值),都可以通过内存域在 proc 文件系统中的接口 /proc/zoneinfo 来查看。比如,下面就是一个 /proc/zoneinfo 文件的内容示例:
$ cat /proc/zoneinfo
...
Node 0, zone Normal
pages free 227894
min 14896
low 18620
high 22344
...
nr_free_pages 227894
nr_zone_inactive_anon 11082
nr_zone_active_anon 14024
nr_zone_inactive_file 539024
nr_zone_active_file 923986
...
这个输出中有大量指标,我来解释一下比较重要的几个。
- pages 处的 min、low、high,就是上面提到的三个内存阈值,而 free 是剩余内存页数,它跟后面的 nr_free_pages 相同。
- nr_zone_active_anon 和 nr_zone_inactive_anon,分别是活跃和非活跃的匿名页数。
- nr_zone_active_file 和 nr_zone_inactive_file,分别是活跃和非活跃的文件页数。
swappiness
到这里,我们就可以理解内存回收的机制了。这些回收的内存既包括了文件页,又包括了匿名页。
- 对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
- 而对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
不过,你可能还有一个问题。既然有两种不同的内存回收机制,那么在实际回收内存时,到底该先回收哪一种呢?其实,Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。虽然 swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整 Swap 积极程度的权重,即使你把它设置成 0,当剩余内存 + 文件页小于页高阈值时,还是会发生 Swap。
实战分析
当 Swap 使用升高时,要如何定位和分析呢?
下面案例基于 Ubuntu 18.04,同样适用于其他的 Linux 系统。
- 机器配置:2 CPU,8GB 内存
- 你需要预先安装 sysstat 等工具,如 apt install sysstat
首先,我们打开两个终端,分别 SSH 登录到两台机器上,并安装上面提到的这些工具。同以前的案例一样,接下来的所有命令都默认以 root 用户运行,如果你是用普通用户身份登陆系统,请运行 sudo su root 命令切换到 root 用户。
然后,在终端中运行 free 命令,查看 Swap 的使用情况。比如,在我的机器中,输出如下:
$ free
total used free shared buff/cache available
Mem: 8169348 331668 6715972 696 1121708 7522896
Swap: 0 0 0
从这个 free 输出你可以看到,Swap 的大小是 0,这说明我的机器没有配置 Swap。为了继续 Swap 的案例, 就需要先配置、开启 Swap。如果你的环境中已经开启了 Swap,那你可以略过下面的开启步骤,继续往后走。要开启 Swap,我们首先要清楚,Linux 本身支持两种类型的 Swap,即 Swap 分区和 Swap 文件。以 Swap 文件为例,在第一个终端中运行下面的命令开启 Swap,我这里配置 Swap 文件的大小为 8GB:
# 创建Swap文件
$ fallocate -l 8G /mnt/swapfile
# 修改权限只有根用户可以访问
$ chmod 600 /mnt/swapfile
# 配置Swap文件
$ mkswap /mnt/swapfile
# 开启Swap
$ swapon /mnt/swapfile
然后,再执行 free 命令,确认 Swap 配置成功:
$ free
total used free shared buff/cache available
Mem: 8169348 331668 6715972 696 1121708 7522896
Swap: 8388604 0 8388604
现在,free 输出中,Swap 空间以及剩余空间都从 0 变成了 8GB,说明 Swap 已经正常开启。接下来,我们在第一个终端中,运行下面的 dd 命令,模拟大文件的读取:
# 写入空设备,实际上只有磁盘的读请求
$ dd if=/dev/sda1 of=/dev/null bs=1G count=2048
接着,在第二个终端中运行 sar 命令,查看内存各个指标的变化情况。你可以多观察一会儿,查看这些指标的变化情况。
# 间隔1秒输出一组数据
# -r表示显示内存使用情况,-S表示显示Swap使用情况
$ sar -r -S 1
04:39:56 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:57 6249676 6839824 1919632 23.50 740512 67316 1691736 10.22 815156 841868 4
04:39:56 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:57 8388604 0 0.00 0 0.00
04:39:57 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:58 6184472 6807064 1984836 24.30 772768 67380 1691736 10.22 847932 874224 20
04:39:57 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:58 8388604 0 0.00 0 0.00
…
04:44:06 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:44:07 152780 6525716 8016528 98.13 6530440 51316 1691736 10.22 867124 6869332 0
04:44:06 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:44:07 8384508 4096 0.05 52 1.27
我们可以看到,sar 的输出结果是两个表格,第一个表格表示内存的使用情况,第二个表格表示 Swap 的使用情况。其中,各个指标名称前面的 kb 前缀,表示这些指标的单位是 KB。去掉前缀后,你会发现,大部分指标我们都已经见过了,剩下的几个新出现的指标,我来简单介绍一下。
- kbcommit,表示当前系统负载需要的内存。它实际上是为了保证系统内存不溢出,对需要内存的估计值。
- %commit,就是这个值相对总内存的百分比。
- kbactive,表示活跃内存,也就是最近使用过的内存,一般不会被系统回收。
- kbinact,表示非活跃内存,也就是不常访问的内存,有可能会被系统回收。
清楚了界面指标的含义后,我们再结合具体数值,来分析相关的现象。你可以清楚地看到,总的内存使用率(%memused)在不断增长,从开始的 23% 一直长到了 98%,并且主要内存都被缓冲区(kbbuffers)占用。具体来说:
- 刚开始,剩余内存(kbmemfree)不断减少,而缓冲区(kbbuffers)则不断增大,由此可知,剩余内存不断分配给了缓冲区。
- 一段时间后,剩余内存已经很小,而缓冲区占用了大部分内存。这时候,Swap 的使用开始逐渐增大,缓冲区和剩余内存则只在小范围内波动。
你可能困惑了,为什么缓冲区在不停增大?这又是哪些进程导致的呢?显然,我们还得看看进程缓存的情况。在前面缓存的案例中我们学过, cachetop 正好能满足这一点。那我们就来 cachetop 一下。在第二个终端中,按下 Ctrl+C 停止 sar 命令,然后运行下面的 cachetop 命令,观察缓存的使用情况:
$ cachetop 5
12:28:28 Buffers MB: 6349 / Cached MB: 87 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
18280 root python 22 0 0 100.0% 0.0%
18279 root dd 41088 41022 0 50.0% 50.0%
通过 cachetop 的输出,我们看到,dd 进程的读写请求只有 50% 的命中率,并且未命中的缓存页数(MISSES)为 41022(单位是页)。这说明,正是案例开始时运行的 dd,导致了缓冲区使用升高。
你可能接着会问,为什么 Swap 也跟着升高了呢?直观来说,缓冲区占了系统绝大部分内存,还属于可回收内存,内存不够用时,不应该先回收缓冲区吗?
这种情况,我们还得进一步通过 /proc/zoneinfo ,观察剩余内存、内存阈值以及匿名页和文件页的活跃情况。
你可以在第二个终端中,按下 Ctrl+C,停止 cachetop 命令。然后运行下面的命令,观察 /proc/zoneinfo 中这几个指标的变化情况:
# -d 表示高亮变化的字段
# -A 表示仅显示Normal行以及之后的15行输出
$ watch -d grep -A 15 'Normal' /proc/zoneinfo
Node 0, zone Normal
pages free 21328
min 14896
low 18620
high 22344
spanned 1835008
present 1835008
managed 1796710
protection: (0, 0, 0, 0, 0)
nr_free_pages 21328
nr_zone_inactive_anon 79776
nr_zone_active_anon 206854
nr_zone_inactive_file 918561
nr_zone_active_file 496695
nr_zone_unevictable 2251
nr_zone_write_pending 0
你可以发现,剩余内存(pages_free)在一个小范围内不停地波动。当它小于页低阈值(pages_low) 时,又会突然增大到一个大于页高阈值(pages_high)的值。再结合刚刚用 sar 看到的剩余内存和缓冲区的变化情况,我们可以推导出,剩余内存和缓冲区的波动变化,正是由于内存回收和缓存再次分配的循环往复。
再结合刚刚用 sar 看到的剩余内存和缓冲区的变化情况,我们可以推导出,剩余内存和缓冲区的波动变化,正是由于内存回收和缓存再次分配的循环往复。
- 当剩余内存小于页低阈值时,系统会回收一些缓存和匿名内存,使剩余内存增大。其中,缓存的回收导致 sar 中的缓冲区减小,而匿名内存的回收导致了 Swap 的使用增大。
- 紧接着,由于 dd 还在继续,剩余内存又会重新分配给缓存,导致剩余内存减少,缓冲区增大。
其实还有一个有趣的现象,如果多次运行 dd 和 sar,你可能会发现,在多次的循环重复中,有时候是 Swap 用得比较多,有时候 Swap 很少,反而缓冲区的波动更大。换句话说,系统回收内存时,有时候会回收更多的文件页,有时候又回收了更多的匿名页。
显然,系统回收不同类型内存的倾向,似乎不那么明显。你应该想到了上节课提到的 swappiness,正是调整不同类型内存回收的配置选项。还是在第二个终端中,按下 Ctrl+C 停止 watch 命令,然后运行下面的命令,查看 swappiness 的配置:
$ cat /proc/sys/vm/swappiness
60
I/O性能分析
网络性能分析
常用分析工具和定位技巧
参考链接:Linux 问题故障定位的技巧大全
参考
- https://xusenqi.site/2020/12/06/C++Profile%E7%9A%84%E5%A4%A7%E6%9D%80%E5%99%A8_gperftools%E7%9A%84%E4%BD%BF%E7%94%A8/
- https://cloud.tencent.com/developer/article/2179443
- https://github.com/gperftools/gperftools
- https://github.com/gperftools/gperftools/wiki
- https://www.cnblogs.com/gary-guo/p/10607514.html
- https://blog.csdn.net/u013051748/article/details/108396621
- https://mp.weixin.qq.com/s?__biz=MzIxMjE1MzU4OA==&mid=2648934092&idx=1&sn=18a29aedac302afb97644efd0e6c84d7&chksm=8f5d4357b82aca41af32f0ac7e8e7c053de6fd14a6c0fe8b31db8574144077b917768969cee1&from=industrynews&version=4.1.6.6020&platform=win#rd
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2023/05/24/performance-tuning-tools/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)