学习背景
在学习Triton、mindspore等深度学习推理框架源码过程中,发现多数框架都支持Linux环境下CPU亲和性、NUMA节点策略配置以及共享内存池,来提高推理框架的性能,源代码部分如下:
//Triton
Status
SetNumaConfigOnThread(
const triton::common::HostPolicyCmdlineConfig& host_policy)
{
// Set thread affinity
RETURN_IF_ERROR(SetNumaThreadAffinity(pthread_self(), host_policy));
// Set memory policy
RETURN_IF_ERROR(SetNumaMemoryPolicy(host_policy));
return Status::Success;
}
//mindspore
auto num_numa_nodes = GetNumaNodeCount();
// If we link with numa library. Set default memory policy.
// If we don't pin thread to cpu, then use up all memory controllers to maximize
// memory bandwidth.
RETURN_IF_NOT_OK(
CacheServerHW::SetDefaultMemoryPolicy(numa_affinity_ ? CachePoolPolicy::kLocal : CachePoolPolicy::kInterleave));
auto my_node = hw_info_->GetMyNode();
MS_LOG(DEBUG) << "Cache server is running on numa node " << my_node;
........
#ifdef CACHE_LOCAL_CLIENT
RETURN_IF_NOT_OK(CachedSharedMemory::CreateArena(&shm_, port_, shared_memory_sz_in_gb_));
// Bring up a thread to monitor the unix socket in case it is removed. But it must be done
// after we have created the unix socket.
auto inotify_f = std::bind(&CacheServerGreeterImpl::MonitorUnixSocket, comm_layer_.get());
RETURN_IF_NOT_OK(vg_.CreateAsyncTask("Monitor unix socket", inotify_f));
#endif
// Spawn a few threads to serve the real request.
auto f = std::bind(&CacheServer::ServerRequest, this, std::placeholders::_1);
for (auto i = 0; i < num_workers_; ++i) {
Task *pTask;
RETURN_IF_NOT_OK(vg_.CreateAsyncTask("Cache service worker", std::bind(f, i), &pTask));
// Save a copy of the pointer to the underlying Task object. We may dynamically change their affinity if needed.
numa_tasks_.emplace(i, pTask);
// Spread out all the threads to all the numa nodes if needed
if (IsNumaAffinityOn()) {
auto numa_id = i % num_numa_nodes;
RETURN_IF_NOT_OK(SetAffinity(*pTask, numa_id));
}
}
共享内存池的相关使用在我之前的文章中有写到过,本篇重点聚焦CPU亲和性和numa节点配置的使用和性能提升。
CPU亲和性
概念
CPU的亲和性,进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性,进程迁移的频率小就意味着产生的负载小。当系统将线程分配给处理器时,操作系统使用亲和性来进行操作。这意味着如果所有其他因素相同的话,它将设法在它上次运行的那个处理器上运行线程。让线程留在单个处理器上,有助于重复使用仍然在处理器的内存高速缓存中的数据。
亲和性一词是从affinity翻译来的,实际可以称为CPU绑定。因此也叫绑核。
在多核计算机中,每个CPU核都有自己的缓存,一旦进程(或线程)被操作系统调度到其他核上,整个缓存都需要重建,缓存的命中率降低,系统性能下降。
在对延迟敏感的系统中,合理地分配进程(或线程)与CPU的亲和性,能够有效提升系统性能,降低延迟。
Linux的CPU亲和性特征
Linux的调度程序同时提供”软CPU亲和性”和”硬CPU亲和性”。
1.软亲和性
进程要在指定的 CPU 上尽量长时间地运行而不被迁移到其他CPU。
Linux 内核进程调度器天生就具有被称为软CPU 亲和性(affinity) 的特性,因此linux通过这种软的亲和性试图使某进程尽可能在同一个CPU上运行。
2.硬亲和性
将进程或者线程绑定到某一个指定的cpu核运行。
虽然Linux尽力通过一种软的亲和性试图使进程尽量在同一个处理器上运行,但它也允许用户强制指定进程无论如何都必须在指定的处理器上运行。
硬亲和性的设置涉及到两个步骤,首先我们需要将核隔离出来,被隔离出来的核不会再被操作系统的调度器使用,也就是说其他的CPU就算再忙,隔离出来的CPU也是空闲的。完成隔离之后,再将进程(或线程)绑定在被隔离出来的CPU上,这样你的程序就只会跑在这个CPU上,并且没有其他任务会来抢占你的CPU。如果只做了绑定步骤,而没有做隔离步骤,虽然程序依然只会跑在被绑定的CPU上,但是其他的任务有权利抢占,导致程序性能会有较大幅度的下降。
接下来所描述的配置都将基于硬亲和性。
3.具体应用
查看CPU的核数
使用cat /proc/cpuinfo查看cpu信息,如下两个信息:
- processor,指明第几个cpu处理器
- cpu cores,指明每个处理器的核心数
总核数 = 物理CPU个数 X 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 查看物理CPU个数 cat /proc/cpuinfo| grep “physical id”| sort| uniq| wc -l 查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo| grep “cpu cores”| uniq 查看逻辑CPU的个数 cat /proc/cpuinfo| grep “processor”| wc -l
使用lscpu可以查看到更具体的信息
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2678 v3 @ 2.50GHz
Stepping: 2
CPU MHz: 1625.366
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4999.88
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb invpcid_single intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts md_clear spec_ctrl intel_stibp flush_l1d
另外使用htop => F2 => columns => PROCESSOR 可以实时查看程序运行在哪个CPU核上
绑核操作
Linux命令绑核
Linux命令可以将进程绑定在具体cpu核上。
写一个简单的不会退出的C语言程序,编译成可执行文件cpu_affinity。
#include <stdio.h>
int main()
{
while (1)
{
printf("cpu_affinity");
}
}
使用taskset命令启动cpu_affinity程序,-c后接该程序需要绑定的cpu id。
# taskset -c 0 ./cpu_affinity
使用htop查看 , cpu_affinity程序仅在cpu1上运行(cpu idx 为0)
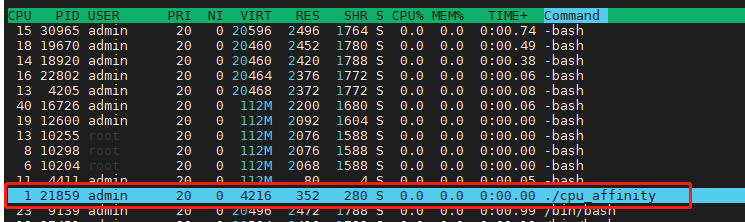
taskset -p {pid} 查看mask:

这里的mask = 1为位掩码, CPU亲和性(affinity)使用位掩码(bitmask)表示,每一位都表示一个CPU, 置1表示“绑定”。 最低位表示第一个逻辑CPU,最高位表示最后一个逻辑CPU。
举例说明:
| bitmask | 含义 |
|---|---|
| 0x00000001 | cpu0 |
| 0x00000003 | cpu0 & cpu1 |
| 0xFFFFFFFF | cpu0到cpu31所有 |
十六进制数e的二进制形式为1110,唯一的一个“0”在最低位,这意味着,除了cpu0不能用,其他的cpu1,2,3都可以使用。
如果程序已经运行起来,可以使用taskset命令在程序运行时绑核(假设绑定在cpu0上)。
# taskset -cp 0 {pid}
Linux API绑核
在Linux中,CPU亲和性掩码数据结构就是cpu_set_t。设置核绑定的方法是CPU_SET。
- 进程绑核
#define _GNU_SOURCE //这个必须定义在#include <sched.h>前
#include <stdio.h>
#include <sched.h>
int main()
{
int cpu_id = 0; // 需要绑定的cpu
cpu_set_t mask; // cpu核的位掩码
CPU_ZERO(&mask); // 置空
CPU_SET(cpu_id, &mask); // 将需要绑定的cpu号设置在mask中
if (sched_setaffinity(0, sizeof(mask), &mask) == -1) // 绑定
{
printf("failed to set affinity.\n");
}
else
{
printf("succeeded to set affinity.\n");
}
// 以上代码即绑定结束,下面代码用于查询绑定情况
cpu_set_t masked;
CPU_ZERO(&masked);
if (sched_getaffinity(0, sizeof(masked), &masked) == -1) // 获取cpu绑定情况
{
printf("failed to get affinity.\n");
}
else
{
// 检查cpu_id是否已经被成功绑定。
if (CPU_ISSET(cpu_id, &masked))
{
printf("succeeded to get affinity.\n");
}
}
while (1)
{
// printf("hello");
}
}
使用gcc编译,需要加上-lpthread
# gcc -o hello main.c -lpthread
直接使用./hello运行该程序,正常情况下会得到如下结果:

查看htop发现进程已经成功绑定在CPU1上

- 线程绑核
// #define _GNU_SOURCE // C++无需引入
#include <thread>
#include <stdio.h>
#include <sched.h>
int main()
{
std::thread
{
[]()
{
int cpu_id = 0; // 需要绑定的cpu
cpu_set_t mask; // cpu核的位掩码
CPU_ZERO(&mask); // 置空
CPU_SET(cpu_id, &mask); // 将需要绑定的cpu号设置在mask中
// 线程绑定方法
if (pthread_setaffinity_np(pthread_self(), sizeof(mask), &mask) == -1)
{
printf("failed to set affinity.\n");
}
else
{
printf("succeeded to set affinity.\n");
}
// 以上代码即绑定结束,下面代码用于查询绑定情况
cpu_set_t masked;
CPU_ZERO(&masked);
// 获取cpu绑定情况
if (pthread_getaffinity_np(pthread_self(), sizeof(masked), &masked) == -1)
{
printf("failed to get affinity.\n");
}
else
{
// 检查cpu_id是否已经被成功绑定。
if (CPU_ISSET(cpu_id, &masked))
{
printf("succeeded to get affinity.\n");
}
}
while (1)
{
// printf("hello");
}
}
}.join();
}
使用g++编译,需要加上-lpthread
# g++ -o hello main.c -lpthread
打开htop我们能看到cpu0已经被hello进程的子线程使用上,绑核成功。


绑核性能测试对比
测试代码:
#include <thread>
#include <stdio.h>
#include <sched.h>
#include <vector>
#include <chrono>
#include <iostream>
#define TIME_STAMP_START(name) auto time_start_##name = std::chrono::steady_clock::now();
#define TIME_STAMP_END(name) \
{ \
auto time_end_##name = std::chrono::steady_clock::now(); \
auto time_cost = std::chrono::duration<double, std::milli>(time_end_##name - time_start_##name).count(); \
std::cout << #name " Time Cost # " << time_cost << " ms ---------------------" << std::endl; \
}
int main()
{
std::thread
{
[]()
{
/*
int cpu_id = 0; // 需要绑定的cpu
cpu_set_t mask; // cpu核的位掩码
CPU_ZERO(&mask); // 置空
CPU_SET(cpu_id, &mask); // 将需要绑定的cpu号设置在mask中
if (pthread_setaffinity_np(pthread_self(), sizeof(mask), &mask) == -1)
{
printf("failed to set affinity.\n");
}
else
{
printf("succeeded to set affinity.\n");
}
cpu_set_t masked;
CPU_ZERO(&masked);
if (pthread_getaffinity_np(pthread_self(), sizeof(masked), &masked) == -1)
{
printf("failed to get affinity.\n");
}
else
{
if (CPU_ISSET(cpu_id, &masked))
{
printf("succeeded to get affinity.\n");
}
}
*/
TIME_STAMP_START(cpu_affinity);
int64_t sum = 0;
// std::cout << "No CPU Affinity\n";
for (size_t i = 0; i < 1000000000; i++)
{
sum += 1;
}
TIME_STAMP_END(cpu_affinity);
}
}.join();
}
测试结果如下,可见绑核后处理能力有一定提升,但当绑定的核心数超过线程数量时,其效率并无明显提高。另外上述测试的前提是CPU资源密集的场景才有效果。
admin@39b648fe04b7:/workspace/tools/test$ ./cpu_affinity
cpu_affinity Time Cost # 2655.82 ms ---------------------
admin@39b648fe04b7:/workspace/tools/test$ ./cpu_affinity
cpu_affinity Time Cost # 2661.5 ms ---------------------
admin@39b648fe04b7:/workspace/tools/test$ taskset -c 0 ./cpu_affinity
cpu_affinity Time Cost # 2586.99 ms ---------------------
admin@39b648fe04b7:/workspace/tools/test$ taskset -c 0 ./cpu_affinity
cpu_affinity Time Cost # 2549.79 ms ---------------------
admin@39b648fe04b7:/workspace/tools/test$ taskset -c 0,10 ./cpu_affinity
cpu_affinity Time Cost # 2547.47 ms ---------------------
admin@39b648fe04b7:/workspace/tools/test$ taskset -c 0,10 ./cpu_affinity
cpu_affinity Time Cost # 2559.86 ms ---------------------
NUMA
前言背景
在NUMA出现之前,CPU朝着高频率的方向发展遇到了天花板,转而向着多核心的方向发展。
在一开始,内存控制器还在北桥中,所有CPU对内存的访问都要通过北桥来完成。此时所有CPU访问内存都是“一致的”,如下图所示:
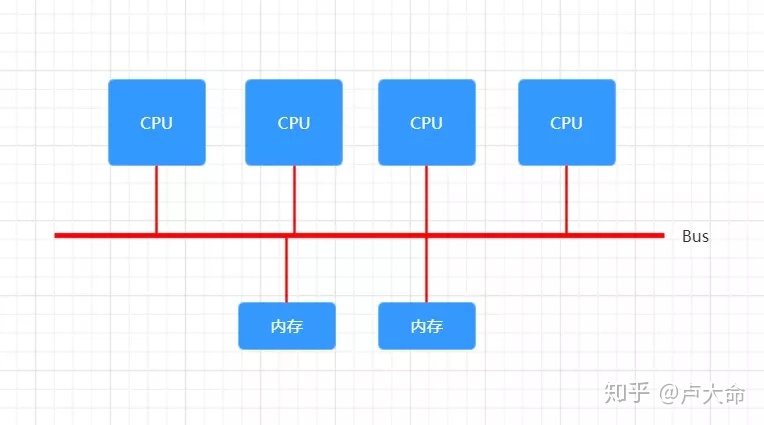
这样的架构称为UMA(Uniform Memory Access),直译为“统一内存访问”,这样的架构对软件层面来说非常容易,总线模型保证所有的内存访问是一致的,即每个处理器核心共享相同的内存地址空间。但随着CPU核心数的增加,这样的架构难免遇到问题,比如对总线的带宽带来挑战、访问同一块内存的冲突问题。为了解决这些问题,有人搞出了NUMA。
概念
NUMA具有多个节点(Node),每个节点可以拥有多个CPU(每个CPU可以具有多个核或线程),节点内使用共有的内存控制器,因此节点的所有内存对于本节点的所有CPU都是等同的,而对于其它节点中的所有CPU都是不同的。节点可分为本地节点(Local Node)、邻居节点(Neighbour Node)和远端节点(Remote Node)三种类型。
本地节点:对于某个节点中的所有CPU,此节点称为本地节点;
邻居节点:与本地节点相邻的节点称为邻居节点;
远端节点:非本地节点或邻居节点的节点,称为远端节点。
邻居节点和远端节点,称作非本地节点(Off Node)。
CPU访问不同类型节点内存的速度是不相同的:本地节点>邻居节点>远端节点。访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作Node Distance。
常用的NUMA系统中:硬件设计已保证系统中所有的Cache是一致的(Cache Coherent, ccNUMA);不同类型节点间的Cache同步时间不一样,会导致资源竞争不公平,对于某些特殊的应用,可以考虑使用FIFO Spinlock保证公平性。
关键信息
1) 物理内存区域与Node号之间的映射关系;
2) 各Node之间的Node Distance;
3) 逻辑CPU号与Node号之间的映射关系。
NUMA构架细节
NUMA 全称 Non-Uniform Memory Access,译为“非一致性内存访问”。这种构架下,不同的内存器件和CPU核心从属不同的 Node,每个 Node 都有自己的集成内存控制器(IMC,Integrated Memory Controller)。
在 Node 内部,架构类似SMP,使用 IMC Bus 进行不同核心间的通信;不同的 Node 间通过QPI(Quick Path Interconnect)进行通信,如下图所示:
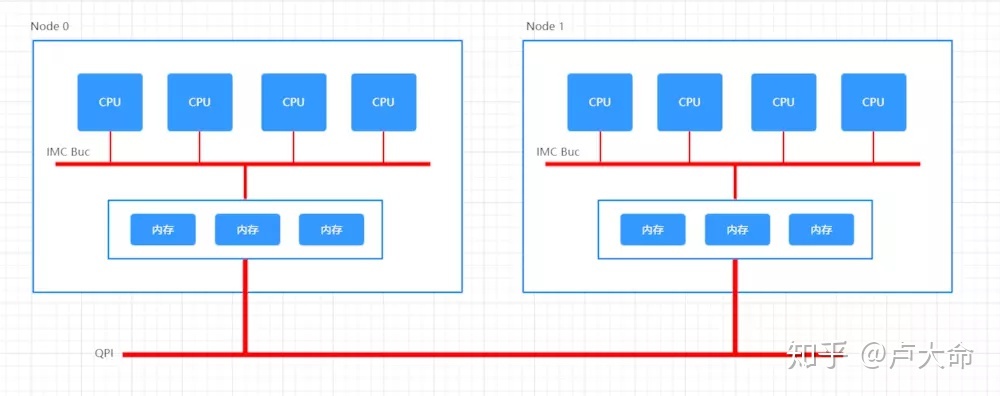
一句话概括:NUMA 指的是针对某个 CPU,内存访问的距离和时间是不一样的。是为了解决多 CPU 系统下共享 BUS 带来的性能问题。(这句话可能不太严谨,不是为了解决,而是事实上解决了。)
NUMA设置
Linux命令行
通过 numactl --hardware 可以查看硬件对NUMA的支持信息:
[jzheng@cr8 /home/jzheng/test]$numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14
node 0 size: 97857 MB
node 0 free: 425 MB
node 1 cpus: 1 3 5 7 9 11 13 15
node 1 size: 163840 MB
node 1 free: 2239 MB
node distances:
node 0 1
0: 10 21
1: 21 10
还有个实用的工具: ` lstopo lstopo –of png > server.png` 可以查看服务器硬件的拓扑结构。
有上述可知:
- CPU被分成两组, node0和node1;
- node0组CPU分配了 大小为95G的内存, node1组CPU分配了160G(该服务器共255G内存);
- node distances 是一个二维矩阵,node[i][j] 表示 node i 访问 node j 的内存的相对距离。比如 node 0 访问 node 0 的内存的距离是 10,而 node 0 访问 node 1 的内存的距离是 21。和 UMA 架构不同,在 NUMA 架构下,内存的访问出现了本地和远程的区别:访问远程内存的延时会明显高于访问本地内存。
执行 numactl --show 显示当前的 NUMA 设置:
[jzheng@cr8 /home/jzheng/test]$numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
cpubind: 0 1
nodebind: 0 1
membind: 0 1
- 当前服务器的NUMA策略为默认;
- 所有的cpu分别绑定在node0和node1上执行;
- numactl 命令还有几个重要选项:
--cpubind=0: 绑定到 node 0 的 CPU 上执行。--membind=1: 只在 node 1 上分配内存。--interleave=nodes:nodes 可以是 all、N,N,N 或 N-N,表示在 nodes 上轮循(round robin)分配内存。--physcpubind=cpus:cpus 是 /proc/cpuinfo 中的 processor(超线程) 字段,cpus 的格式与 –interleave=nodes 一样,表示绑定到 cpus 上运行。--preferred=1: 优先考虑从 node 1 上分配内存。
- numactl 命令的几个例子:
# 运行 test_program 程序,参数是 argument,绑定到 node 0 的 CPU 和 node 1 的内存
numactl --cpubind=0 --membind=1 test_program arguments
# 在 processor 0-4,8-12 上运行 test_program
numactl --physcpubind=0-4,8-12 test_program arguments
# 轮询分配内存
numactl --interleave=all test_program arguments
# 优先考虑从 node 1 上分配内存
numactl --preferred=1
命令行测试
#include <thread>
#include <stdio.h>
#include <sched.h>
#include <vector>
#include <chrono>
#include <iostream>
#define TIME_STAMP_START(name) auto time_start_##name = std::chrono::steady_clock::now();
#define TIME_STAMP_END(name) \
{ \
auto time_end_##name = std::chrono::steady_clock::now(); \
auto time_cost = std::chrono::duration<double, std::milli>(time_end_##name - time_start_##name).count(); \
std::cout << #name " Time Cost # " << time_cost << " ms ---------------------" << std::endl; \
}
int main()
{
std::thread
{
[]()
{
TIME_STAMP_START(numa_node);
int64_t size = 2000;
// 按列遍历,避免 CPU cache 的影响
std::vector<std::vector<uint64_t>> data(size, std::vector<uint64_t>(size));
for (int col = 0; col < size; ++col) {
for (int row = 0; row < size; ++row) {
data[row][col] = rand();
}
}
TIME_STAMP_END(numa_node);
}
}.join();
return 0;
}
实测结果:
---------------第一次对比
[jzheng@cr8 /home/jzheng/test]$numactl --cpubind=1 --membind=1 ./numa_node
numa_node Time Cost # 229.36 ms ---------------------
[jzheng@cr8 /home/jzheng/test]$numactl --cpubind=0 --membind=1 ./numa_node
numa_node Time Cost # 274.399 ms ---------------------
---------------第二次对比
[jzheng@cr8 /home/jzheng/test]$numactl --cpubind=1 --membind=1 ./numa_node
numa_node Time Cost # 231.561 ms ---------------------
[jzheng@cr8 /home/jzheng/test]$numactl --cpubind=0 --membind=1 ./numa_node
numa_node Time Cost # 278.001 ms ---------------------
可以看出 CPU访问距离较远的numa节点时会比访问本地内存节点速度慢,大概慢20%以上。
Linux API
头文件为
#include <numa.h>
#include <numaif.h>
//策略设置接口,具体实用通过man set_mempolicy查看
int set_mempolicy(int mode, unsigned long *nodemask, unsigned long maxnode);
NUMA策略
随着系统中的CPU和内存增加,物理上将内存分成了numa节点。而运行时系统从哪个节点上分配内存就会影响到系统运行的性能。
内核当然可以提供一种默认的分配策略,而同时用户或许也会希望能够设置自己的分配行为。
今天我们就来看看内核提供了哪些分配策略,又是如何实现的。
最关键的数据结构 – mempolicy
对我来说,每次要学习一个新的概念,最关键的就是学习这个概念背后的数据结构,而算法则是对数据结构的一个操作。
在numa策略中,内核最关键的数据结构是mempolicy。
mempolicy
+------------------------------+
|refcnt |
| (atomic_t) |
|mode |
|flags |
| (unsigned short) |
|v |
| +--------------------------+
| |preferred_node |
| | (short) |
| |nodes |
| | (nodemask_t) |
| +--------------------------+
|w |
| +--------------------------+
| |cpuset_mems_allowed |
| |user_nodemask |
| | (nodemask_t) |
+---+--------------------------+
这个结构相对来说是简单的。其中最重要的就是mode成员:
- mode 指定了策略的模式
知道了这个策略的模式,你就大致能猜到策略的运作和其他成员的含义。那我们就来看看内核当前都有哪些模式:
enum {
MPOL_DEFAULT,
MPOL_PREFERRED,
MPOL_BIND,
MPOL_INTERLEAVE,
MPOL_LOCAL,
MPOL_MAX, /* always last member of enum */
};
具体每个策略的含义暂且不表,因为这个可以在网上直接搜到。而我们想要说的是,这个数据结构是如何影响到一个进程的内存分配的。
mempolicy和进程的关联
既然是要控制进程的内存分配策略,那么必然这个数据结构就要和进程发生关系,否则怎么能够控制到进程呢?
这时候,还是数据结构能帮上忙。
task_struct
+----------------------+
|mempolicy |
| (struct mempolicy*)|
|mm |
| (struct mm_struct*)|
+----------------------+
/ \
/ \
/ \
/ \
vma vma
+------------------------+ +------------------------+
|vm_ops | |vm_ops |
| get_policy | | get_policy |
| | | |
|vm_policy | |vm_policy |
| (struct mempolicy*) | | (struct mempolicy*) |
+------------------------+ +------------------------+
从这个结构中我们可以看到,在进程和vma级别都有各自的mempolicy指针。当我们在分配内存时,就会根据对应的mempolicy来分配。
那接下来我们就要回答两个问题:
- 如何设置mempolicy
- mempolicy如何影响分配
设置mempolicy的用户态接口
首先我们来回答第一个问题–如何设置mempolicy。因为mempolicy分别在进程和vma两个层次,所以内核提供了对应的两个接口来设置。
- set_mempolicy
- mbind
设置进程级numa策略 – set_mempolicy
首先是进程级别的numa策略设置,由函数set_mempolicy来负责。
具体函数的含义大家查找man就可以了,我们这里来看看这个函数干的活。
set_mempolicy() -> kernel_set_mempolicy()
get_nodes(&nodes, nmask, maxnode)
do_set_mempolicy(mode, flags, &nodes)
new = mpol_new(mode, flags, nodes)
task_lock(current)
mpol_set_nodemask(new, nodes, scratch)
old = current->mempolicy
current->mempolicy = new
task_unlock(current)
mpol_put(old)
打开一看其实很简单,就是给task_struct上新安装一个mempolicy。得嘞。
设置区域级numa策略 – mbind
除了进程级别的numa策略,内核还提供了vma级别细粒度的策略设置,由函数mbind来负责。
mbind函数除了设置vma级别的numa策略,还会做内存迁移。所以这个函数实际上是做了两件事情。
mbind(start, len, mode, nmask, maxnode, flags) -> kernel_mbind()
get_nodes(&nodes, nmask, maxnode)
do_mbind(start, len, mode, mode_flags, &nodes, flags)
new = mpol_new(mode, mode_flags, nmask)
migrate_prep()
lru_add_drain_all()
queue_pages_range(mm, start, end, nmask, flags | MPOL_MF_INVERT, &pagelist)
mbind_range(mm, start, end, new)
migrage_pages(&pagelist, new_page, NULL, start, )
所以整个函数只有在mbind_range上才是去更新vma对应的策略,其他的步骤都是为了做内存迁移准备的。
numa策略的作用
了解了策略的数据结构,了解了这个结构和进程之间的关系,也了解了如何设置策略,那么接下来就是要看看这个设置好的策略究竟如何起作用了。
大家猜猜,内核中会在哪些地方起作用呢?嗯,对了,至少有两个地方会发挥numa策略的作用。
- page fault
- numa balance
首先是在缺页处理时当然会按照当前的策略去分配内存,其次就是会动态的检测进程的内存是否符合当前的策略并进行相应的调整。
page fault
发生缺页异常时,内核会去分配内存并将页表填好。此时就会考虑到从哪里去分配内存,在这个时候就会去参考之前设置的numa策略。
do_anonymous_page()
alloc_zeroed_user_highpage_movable() -> __alloc_zeroed_user_highpage()
alloc_pages_vma(), alloc with NUMA policy(understand how policy works)
pol = get_vma_policy(vma, addr), pol from vma or task policy
alloc_page_interleave(), if pol->mode == MPOL_INTERLEAVE
nmask = policy_nodemask()
比如说在我们熟悉的do_anonymous_page()过程中需要去分配页,就会调用alloc_pages_vma()根据对应的mempolicy来分配。
参考
- https://zhuanlan.zhihu.com/p/461928365
- https://blog.csdn.net/qq_38232598/article/details/114263105
- https://zhuanlan.zhihu.com/p/336365600
- https://zhuanlan.zhihu.com/p/62795773
- https://zhuanlan.zhihu.com/p/67558970
- https://richardweiyang-2.gitbook.io/kernel-exploring/00-index/07-mempolicy
文档信息
- 本文作者:JianZheng
- 本文链接:https://zhengjian526.github.io/left-handed_knife//2023/03/05/CPU-affinity-and-numa-node/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)