Cache高速缓存相关基本概念
为什么需要高速缓存?
为了弥补CPU性能和内存访问性能之间的性能差异,我们能真实地把 CPU 的性能提升用起来,而不是让它在那儿空转,我们在现代 CPU 中引入了高速缓存。
从 CPU Cache 被加入到现有的 CPU 里开始,内存中的指令、数据,会被加载到 L1-L3Cache 中,而不是直接由 CPU 访问内存去拿。在 95% 的情况下,CPU 都只需要访问 L1-L3 Cache,从里面读取指令和数据,而无需访问内存。要注意的是,这里我们说的 CPU Cache 或者 L1/L3 Cache,不是一个单纯的、概念上的缓存(比如之前我们说的拿内存作为硬盘的缓存),而是指特定的由 SRAM 组成的物理芯片。
CPU经典cache架构图:
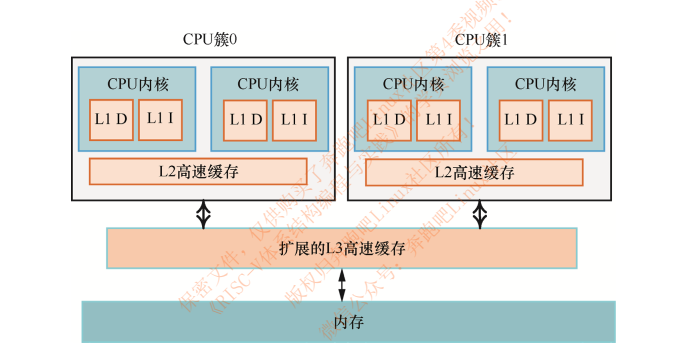
Cache Line
高速缓存的内部由高速缓存行组成,也就是Cache Line。现代cpu都带有缓存,一般分为3级,离cpu越近的缓存存取速度越快,同时缓存的容量越小。现代cpu的一级缓存一般大小为4~64k,并且存取时是以cache line的形式进行的。我们日常使用的cpu cache line一般64字节,也就是cpu在读取数据时会一次性的从上级内存将64字节的数据读取到当前缓存中。因此,当我们要读取一个long类型的数据时,cpu实际上会将和它临近的一些字节一起读取到一级缓存中,以满足一次读取一个cache line的要求。
linux系统中可以通过cat /sys/devices/system/cpu/cpu1/cache/index0/coherency_line_size 命令行查看cache line的size,常用CPU的cache line size为64字节。
下图为Cache内部结构图:
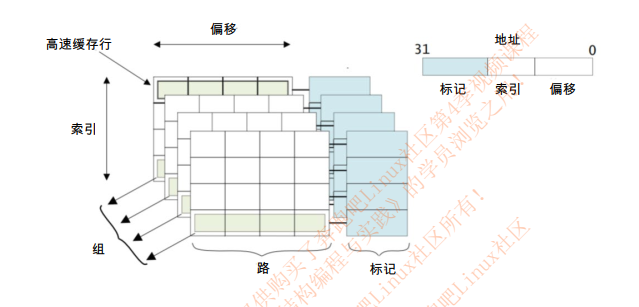
- 高速缓存行(cache line):高速缓存中最小的访问单元;
- 索引(index)域:用于索引和查找是在高速缓存中的哪一行;
- 标记(tag):高速缓存地址编码的一部分,通常是高速缓存地址的高位部分,用来判断高速缓存行缓存数据的地址是 否和处理器寻址地址一致;
- 偏移(offset) :高速缓存行中的偏移。处理器可以按字(word)或者字节(Byte)来寻址高速缓存行的内容;
- 组(set):相同索引域的高速缓存行组成一个组;
- 路(way):在组相联的高速缓存中,高速缓存被分成大小相同的几个块。
内存地址到Cache Line的关系
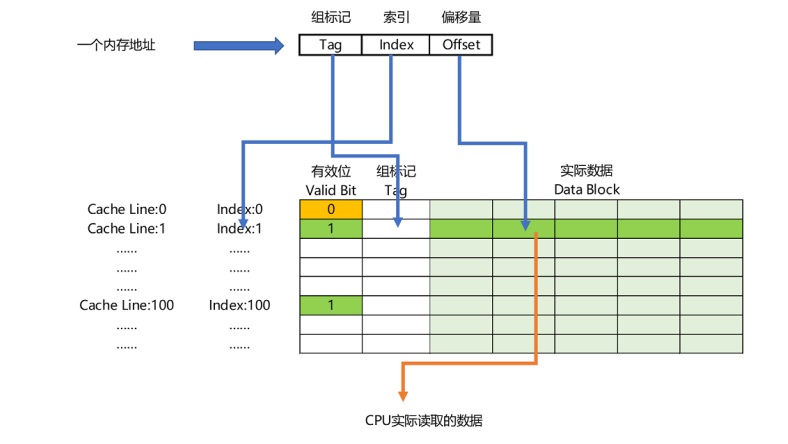
内存地址对应到 Cache 里的数据结构,则多了一个有效位和对应的数据,由“索引 + 有效位 + 组标记 + 数据”组成。如果内存中的数据已经在 CPU Cache 里了,那一个内存地址的访问,就会经历这样 4 个步骤:
- 根据内存地址的低位,计算在 Cache 中的索引;
- 判断有效位,确认 Cache 中的数据是有效的;
- 对比内存访问地址的高位,和 Cache 中的组标记,确认 Cache 中的数据就是我们要访问的内存数据,从 Cache Line 中读取到对应的数据块(Data Block);
- 根据内存地址的 Offset 位,从 Data Block 中,读取希望读取到的字。
如果在 2、3 这两个步骤中,CPU 发现,Cache 中的数据并不是要访问的内存地址的数据,那 CPU 就会访问内存,并把对应的 Block Data 更新到 Cache Line 中,同时更新对应的有效位和组标记的数据 。
缓存一致性(cache coherency)
cache一致性关注的是同一个数据在多个高速缓存和内存中的一致性问题,解决高速缓存一致性 的方法主要是总线监听协议,例如MESI协议等。
缓存一致性的解决方案–总线嗅探机制和MESI协议
要解决缓存一致性问题,首先要解决的是多个 CPU 核心之间的数据传播问题。最常见的一种解决方案呢,叫作总线嗅探(Bus Snooping)。这个名字听起来,你多半会很陌生,但是其实特很好理解。 这个策略,本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。总线本身就是一个特别适合广播进行数据传输的机制,所以总线嗅探这个办法也是我们日常使用的 Intel CPU 进行缓存一致性处理的解决方案。关于总线这个知识点,我们会放在后面的 I/O 部分更深入地进行讲解,这里你只需要了解就可以了。 基于总线嗅探机制,其实还可以分成很多种不同的缓存一致性协议。不过其中最常用的,就是今天我们要讲的 MESI 协议。和很多现代的 CPU 技术一样,MESI 协议也是在Pentium 时代,被引入到 Intel CPU 中的。MESI 协议,是一种叫作写失效(Write Invalidate)的协议。在写失效协议里,只有一个CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。 相对于写失效协议,还有一种叫作写广播(Write Broadcast)的协议。在那个协议里,一个写入请求广播到所有的 CPU 核心,同时更新各个核心里的 Cache。写广播在实现上自然很简单,但是写广播需要占用更多的总线带宽。写失效只需要告诉其他的 CPU 核心,哪一个内存地址的缓存失效了,但是写广播还需要把对应的数据传输给其他 CPU 核心。
MESI协议
MESI 协议的由来呢,来自于我们对 Cache Line 的四个不同的标记,分别是: M:代表已修改(Modified) E:代表独占(Exclusive) S:代表共享(Shared) I:代表已失效(Invalidated)
| 状态 | 描述 |
|---|---|
| M | 这行数据有效,数据被修改,与内存中的数据不一致,数据只存在本高速缓存中 |
| E | 这行数据有效,数据与内存中数据一致,数据只存在本高速缓存中 |
| S | 这行数据有效,数据与内存中数据一致,多个高速缓存由这个数据副本 |
| I | 这行数据无效 |
- 修改和独占状态的cache line,数据都是独有的,不同点在于修改状态的数据是脏的,和内存不一致,而 独占态的数据是干净的和内存一致。 脏的cache line会被回写到内存,其后的状态变成共享态。
- 共享状态的cache line,数据和其他cache共享,只有干净的数据才能被多个cache共享。
MESI 协议的四种状态之间的流转过程如下表,可以详细看到每种状态转换的原因:
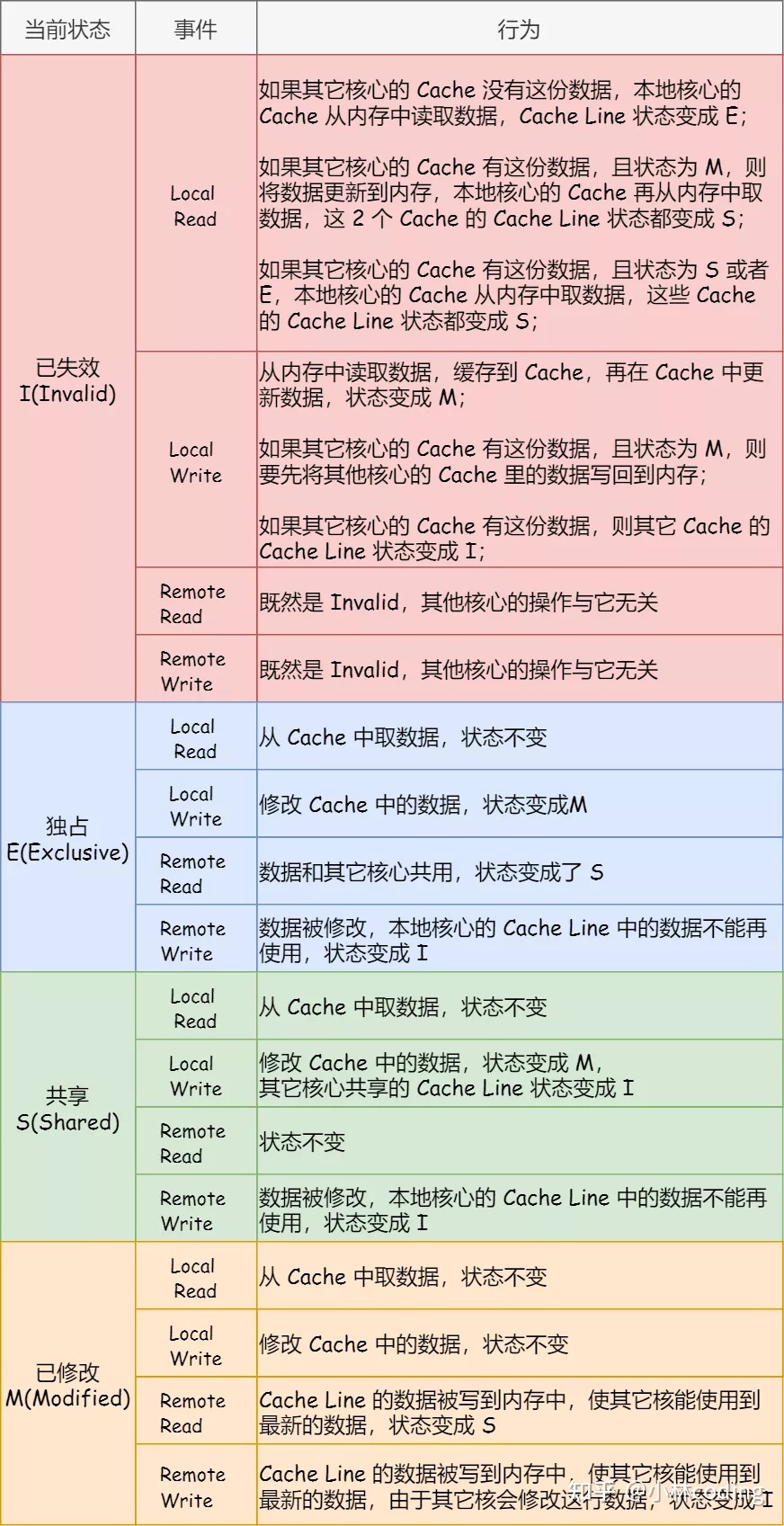
具体学习可以参考《RISC-V体系结构编程与实践》的缓存一致性章节。
高速缓存伪共享
如果多个处理器同时访问一个缓存行中不同的数据时,带来了性能上的问题。具体实例可以参考《RISC-V体系结构编程与实践》中的伪共享实例,书中实例可以看出,当出现伪共享时多个cpu的cache line会频繁的修改状态,进而导致性能问题。后续也会通过代码实例进行说明。
高速缓存伪共享的解决办法就是让多线程操作的数据处在不同的高速缓存行,通常可以采用高速缓存行填充 (padding)技术或者高速缓存行对齐(align)技术,即让数据结构按照高速缓存行对齐,并且尽可能填充满 一个高速缓存行大小。
C++ 代码实例说明
可以参考 这篇文章,文中的实例我已经测试过了,跟着走一遍可以便于理解内存对齐、cache line和伪共享对C++程序性能的影响。
C++17中关于高速缓存伪共享的解决方法
在C++17中引入了std::hardware_destructive_interference_size和std::hardware_constructive_interference_size两个变量解决伪共享问题。在头文件
在标头 <new> 定义 | ||
|---|---|---|
| inline constexpr std::size_t hardware_destructive_interference_size = /*implementation-defined*/; | (1) | (C++17 起) |
| inline constexpr std::size_t hardware_constructive_interference_size = /*implementation-defined*/; | (2) | (C++17 起) |
(1)两个对象间避免假数据共享的最小偏移。保证至少为 alignof(std::max_align_t)
struct keep_apart {
alignas(std::hardware_destructive_interference_size) std::atomic<int> cat;
alignas(std::hardware_destructive_interference_size) std::atomic<int> dog;
};
(2)促使真共享内存达成最大的连续内存大小。保证至少为 alignof(std::max_align_t)
struct together {
std::atomic<int> dog;
int puppy;
};
struct kennel {
// 其他数据成员……
alignas(sizeof(together)) together pack;
// 其他数据成员……
};
static_assert(sizeof(together) <= std::hardware_constructive_interference_size);
注解
这些常量提供一种可移植的访问 L1 数据缓存线大小的方式。
| Feature-test macro | Value | Std |
|---|---|---|
__cpp_lib_hardware_interference_size | 201703L | (C++17) |
代码实例
该程序使用两个线程(自动地)写入给定全局对象的数据成员。第一个对象放在一条缓存线上,这导致了“硬件干扰”。第二个对象将其数据成员保存在单独的缓存线上,因此避免了线程写入后可能的“缓存同步”。
#include <atomic>
#include <chrono>
#include <cstddef>
#include <iomanip>
#include <iostream>
#include <mutex>
#include <new>
#include <thread>
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 64 bytes on x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │ ...
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
std::mutex cout_mutex;
constexpr int max_write_iterations{10'000'000}; // the benchmark time tuning
struct alignas(hardware_constructive_interference_size)
OneCacheLiner { // occupies one cache line
std::atomic_uint64_t x{};
std::atomic_uint64_t y{};
} oneCacheLiner;
struct TwoCacheLiner { // occupies two cache lines
alignas(hardware_destructive_interference_size) std::atomic_uint64_t x{};
alignas(hardware_destructive_interference_size) std::atomic_uint64_t y{};
} twoCacheLiner;
inline auto now() noexcept { return std::chrono::high_resolution_clock::now(); }
template<bool xy>
void oneCacheLinerThread() {
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
oneCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else oneCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed { now() - start };
std::lock_guard lk{cout_mutex};
std::cout << "oneCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
oneCacheLiner.x = elapsed.count();
else oneCacheLiner.y = elapsed.count();
}
template<bool xy>
void twoCacheLinerThread() {
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
twoCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else twoCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed { now() - start };
std::lock_guard lk{cout_mutex};
std::cout << "twoCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
twoCacheLiner.x = elapsed.count();
else twoCacheLiner.y = elapsed.count();
}
int main() {
std::cout << "__cpp_lib_hardware_interference_size "
# ifdef __cpp_lib_hardware_interference_size
" = " << __cpp_lib_hardware_interference_size << '\n';
# else
"is not defined, use " << hardware_destructive_interference_size << " as fallback\n";
# endif
std::cout
<< "hardware_destructive_interference_size == "
<< hardware_destructive_interference_size << '\n'
<< "hardware_constructive_interference_size == "
<< hardware_constructive_interference_size << "\n\n";
std::cout
<< std::fixed << std::setprecision(2)
<< "sizeof( OneCacheLiner ) == " << sizeof( OneCacheLiner ) << '\n'
<< "sizeof( TwoCacheLiner ) == " << sizeof( TwoCacheLiner ) << "\n\n";
constexpr int max_runs{4};
int oneCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i) {
std::thread th1{oneCacheLinerThread<0>};
std::thread th2{oneCacheLinerThread<1>};
th1.join(); th2.join();
oneCacheLiner_average += oneCacheLiner.x + oneCacheLiner.y;
}
std::cout << "Average T1 time: " << (oneCacheLiner_average / max_runs / 2) << " ms\n\n";
int twoCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i) {
std::thread th1{twoCacheLinerThread<0>};
std::thread th2{twoCacheLinerThread<1>};
th1.join(); th2.join();
twoCacheLiner_average += twoCacheLiner.x + twoCacheLiner.y;
}
std::cout << "Average T2 time: " << (twoCacheLiner_average / max_runs / 2) << " ms\n\n";
std::cout << "Ratio T1/T2:~ " << 1.*oneCacheLiner_average/twoCacheLiner_average << '\n';
}
C++17编译器下运行:
__cpp_lib_hardware_interference_size = 201703
hardware_destructive_interference_size == 64
hardware_constructive_interference_size == 64
sizeof( OneCacheLiner ) == 64
sizeof( TwoCacheLiner ) == 128
oneCacheLinerThread() spent 340.88 ms
oneCacheLinerThread() spent 342.55 ms
oneCacheLinerThread() spent 191.77 ms
oneCacheLinerThread() spent 218.80 ms
oneCacheLinerThread() spent 171.79 ms
oneCacheLinerThread() spent 199.28 ms
oneCacheLinerThread() spent 200.48 ms
oneCacheLinerThread() spent 226.31 ms
Average T1 time: 235 ms
twoCacheLinerThread() spent 52.40 ms
twoCacheLinerThread() spent 52.41 ms
twoCacheLinerThread() spent 53.90 ms
twoCacheLinerThread() spent 53.91 ms
twoCacheLinerThread() spent 52.36 ms
twoCacheLinerThread() spent 52.35 ms
twoCacheLinerThread() spent 52.46 ms
twoCacheLinerThread() spent 52.47 ms
Average T2 time: 52 ms
Ratio T1/T2:~ 4.51
代码示例中T1时间为结构体oneCacheLiner在两个线程中分别修改和访问原子变量x 和 y的平均时间,该结构体中x和y 位于同一个cache line中,发生了伪共享现象; 在twoCacheLiner中则是解决了伪共享。通过最后的Ratio T1/T2:~ 4.51可以得知, oneCacheLiner所用的时间是 twoCacheLiner的4.51倍,可见高速缓存伪共享会极大程度上减低程序执行效率。
参考
- https://zhuanlan.zhihu.com/p/468636398
- https://blog.51cto.com/u_6650004/5997218
- https://zh.cppreference.com/w/cpp/thread/hardware_destructive_interference_size
- 《RISC-V体系结构编程与实践》